Tests de pénétration IA & LLM – Simulations d'attaques pour des systèmes d'IA sécurisés et conformes à l'AI Act
Sécurisez durablement vos systèmes d'IA et vos LLM contre les attaques telles que l'injection de prompts, l'exfiltration de données et les exploits agentiques. Tests de pénétration IA réels selon les normes OWASP + conformité AI Act & NIS2.

OWASP Top 10 für Agentic Applications: Live Demo
Maschinen gegen Maschinen — Valeri Milke und Lucas Murtfeld zeigen Offensive und Defensive in der Ära der KI. Mit Live-Hack zu Prompt Injection.
Hinweis: KI erweitert die Angriffsfläche über klassische Software hinaus — früh testen reduziert Incident-, Compliance- und Audit-Risiken.
Les tests de pénétration IA sont essentiels
L'IA élargit fondamentalement la surface d'attaque au-delà des logiciels traditionnels. Les prompts, les données de contexte, les pipelines de données et la logique agentique deviennent des points de risque indépendants.
- Nouvelles classes d'attaques : Prompt Injection, Data Poisoning, Model Extraction – sans précédent dans la sécurité traditionnelle
- Non déterministe : les LLM ne suivent aucune logique fixe – l'analyse statique et les signatures ne s'appliquent pas
- Surface d'attaque élargie : entraînement, inférence, API, plugins, agents – chaque phase est attaquable
- Pression réglementaire : l'EU AI Act, NIS2, DORA et le RGPD exigent des mesures de sécurité IA démontrables
- OWASP Top 10 pour les applications agentiques 2026
- Cartographié MITRE ATLAS, NIST AI RMF, EU AI Act ready, ISO 27001 / 42001
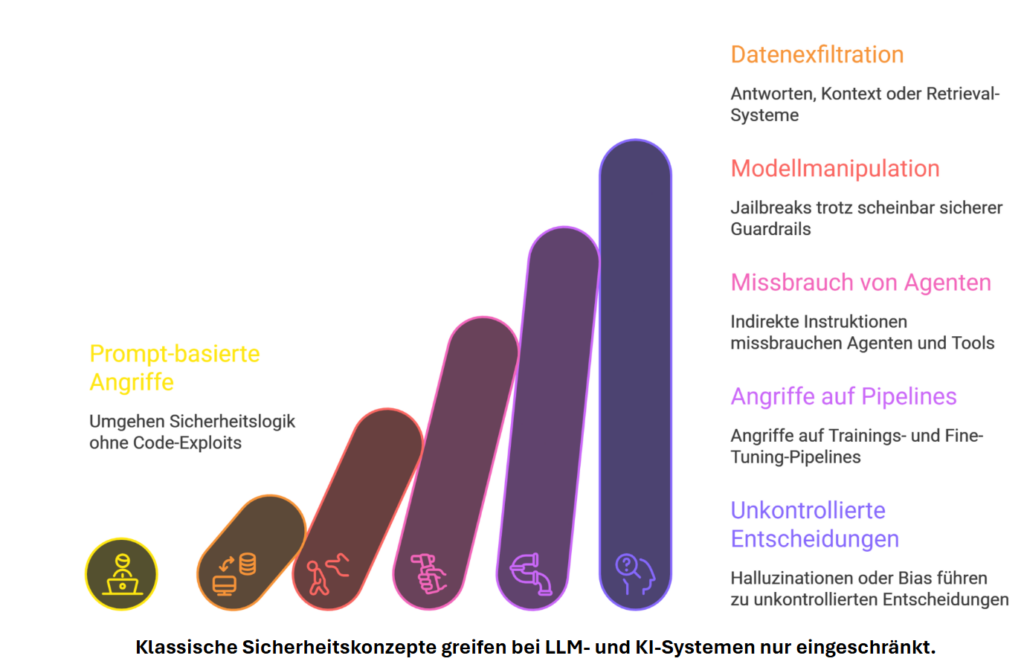
Six niveaux de menaces IA
Des ruses subtiles de prompts aux décisions incontrôlées — chaque niveau intensifie le risque et déjoue les concepts de sécurité classiques.
Menaces de sécurité pour l'IA & les LLM
Vue d'ensemble des menaces et vulnérabilités typiques des systèmes d'IA et de LLM en production — point de départ pour des pentests structurés.

Entrée
Prompt injection, jailbreaks, documents non fiables (PDF, pièces jointes e-mail).

Données & contexte
Exfiltration, manipulation RAG/embedding, memory poisoning.

Chaîne d'approvisionnement
Modèles, LoRA, plugins, API — intégrité sur tout le cycle de vie.

Sortie
Improper Output Handling, XSS/injection dans les systèmes en aval.

Agentique
Mauvais usage des outils, détournement d'objectifs, permissions excessives.

Exploitation
Consommation illimitée, shadow AI, journalisation et application des politiques manquantes.
Unser CISO-Leitfaden zur KI-Sicherheit und Red Teaming
Praxisnahe Einordnung für CISOs und Security-Leads — von Bedrohungslandschaft bis zu konkreten Test- und Governance-Ansätzen.
Inhalt auf einen Blick
Threat Landscape für LLM & Agents, Pentest- und Red-Team-Methodik, Abgrenzung zu klassischer AppSec, Checklisten für Governance und Audit-Gespräche.

Unternehmen stehen vor strukturellen KI-Sicherheitsherausforderungen
Organisationen integrieren KI und LLMs rasant — oft schneller, als Sicherheits-, Risiko- und Governance-Kontrollen nachziehen.
Nicht stehen bleiben — aber auch nicht rasen
Sichtbarkeit im Betrieb
KI-Risiken entstehen im laufenden Betrieb — Pentests machen sie sichtbar und beherrschbar.
Business & Remediation
Schutz vor Daten- und Geschäftsrisiken; realitätsnahes Sicherheitsbild und konkrete Remediation.
Regulatorik
Compliance-Alignment: EU AI Act, NIS2 und Audit-Readiness.
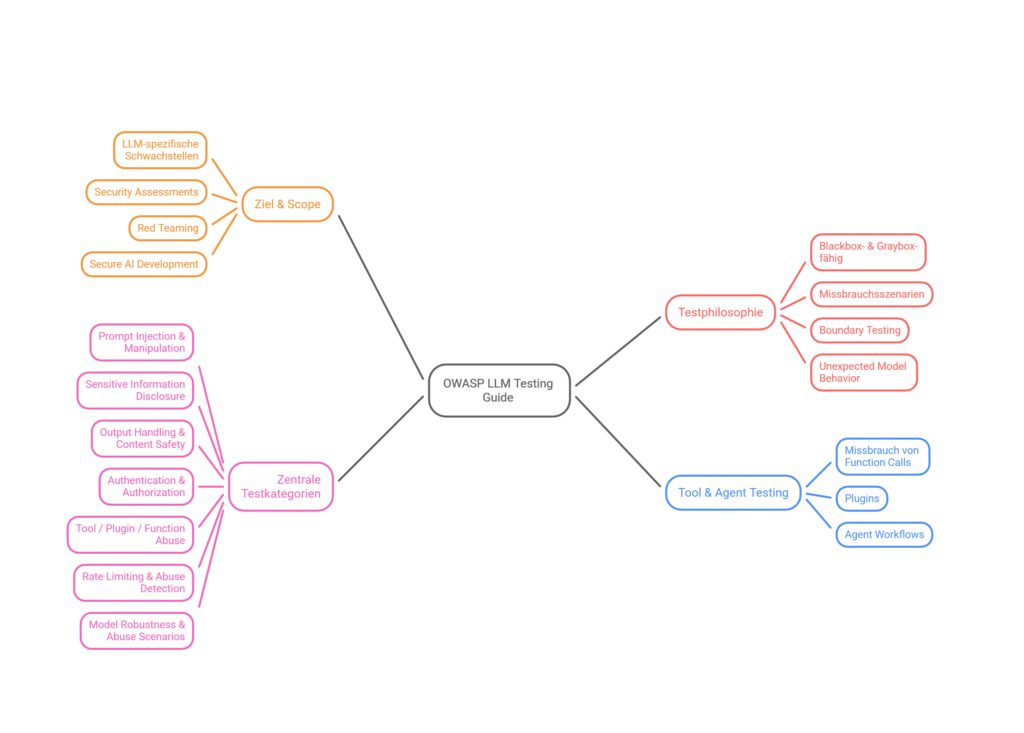
OWASP Top 10 for LLM Applications
Les 10 risques de sécurité les plus critiques pour les grands modèles de langage — la base de notre méthodologie de test.
Prompt Injection
Instructions malveillantes dans les entrées qui manipulent le comportement du LLM.
Sensitive Information Disclosure
Données confidentielles exposées via les sorties ou les configurations.
Supply Chain
Modèles, jeux de données ou bibliothèques tiers compromis.
Data & Model Poisoning
Manipulation des données d'entraînement ou de fine-tuning pour des portes dérobées.
Improper Output Handling
Sorties LLM transmises sans validation aux systèmes en aval.
Excessive Agency
Trop d'autonomie pour les agents LLM — actions non intentionnelles.
System Prompt Leakage
Les prompts système sont divulgués ou déduits.
Vector & Embedding Weakness
Attaques sur les pipelines RAG et les bases de données d'embeddings.
Misinformation
Informations fausses ou trompeuses qui semblent crédibles.
Unbounded Consumption
Consommation excessive de ressources par des requêtes d'inférence non contrôlées.
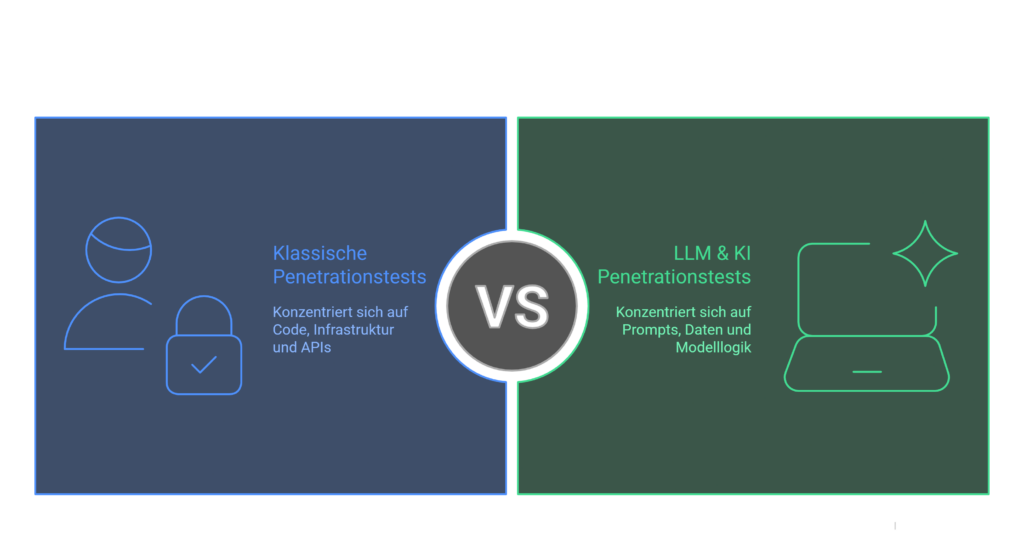
Vergleich von Web- und KI-Anwendungssicherheit
Applikationssicherheit bleibt das Fundament für NIS2 und AI Act — LLMs erweitern die Angriffsfläche um Prompts, Kontextdaten und agentische Workflows.
- Injection, Broken Access Control, XSS, SSRF auf HTTP/API-Ebene
- Stateful Sessions, serverseitige Validierung, bekannte OWASP-Web-Top-10-Muster
- Fokus: Requests, Responses, serverseitige Logik
- Prompt Injection, kontextbasierte Manipulation, Jailbreaks
- RAG/Embeddings, Tool-Calling, Multi-Agent-Ketten, Datenexfiltration
- Fokus: Kontextfenster, Policies, agentische Entscheidungen
OWASP ASVS 5.0 bündelt ~350 Security Requirements für Anwendungen. OWASP ASVS 5.0 — vollständige Seite →
Produktionsnahes KI-Security-Testing
KI-Pentesting mit technischer Tiefe — strukturiert, reproduzierbar und auditfähig für reale Produktionsumgebungen.
IA agentique : plus d'autonomie = plus de surface d'attaque
Les agents autonomes exécutent des outils et conservent du contexte — des risques que les tests de sécurité classiques ne couvrent souvent pas. Référence : OWASP Top 10 for Agentic Applications (2026).
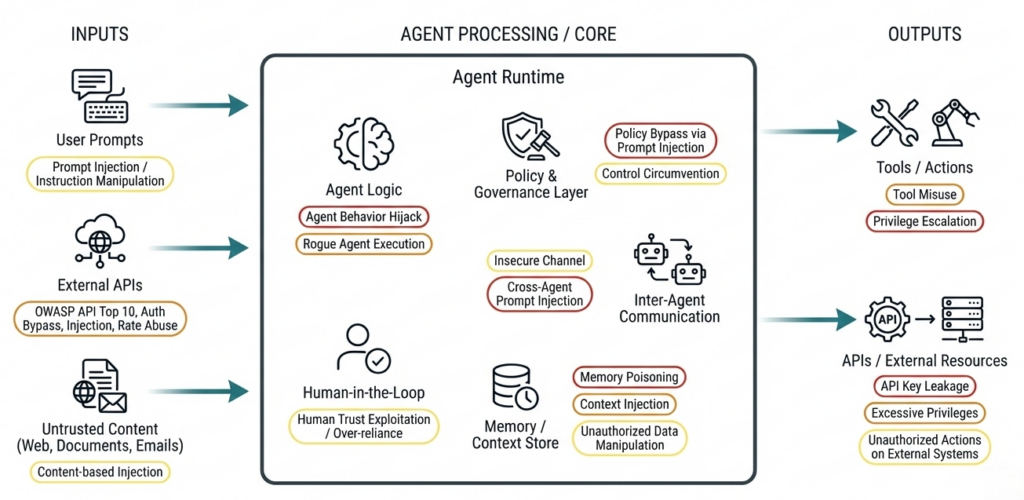
Reale Angriffe auf Agentic AI Systems
- Mauvais usage d'outils, détournement d'objectifs & fuites de mémoire
- Sélection d'outils & chaînage de contexte non sécurisés
- Abus d'identité (humain ↔ agent)
- Prompt injection dans des workflows multi-agents
- Confusion de modèle & risques de délégation
Nous vérifions systématiquement : quelles actions les agents peuvent exécuter, comment le contexte circule entre agents, outils et workflows, et la sécurité des décisions, boucles et exécutions d'outils.
Risques sécurité & techniques
Hijacking, prompt injection, exposition de données — une surface d'attaque étendue.
Risques opérationnels & de contrôle
Une confiance excessive sans human-in-the-loop peut faire perdre le contrôle.
Business & conformité
AI Act, RGPD — gestion structurée du risque IA.
Société & éthique
Désinformation, deepfakes — secure-by-design et tests réguliers.
AI & LLM Security CTF
Typische Angriffspfade wie Prompt Injection, Tool- und Agent-Missbrauch sowie unsichere Ausgabe- und Datenverarbeitung — praktisch nachvollziehbar, realistisch und enterprise-tauglich.
Datenabfluss verhindern: Ihre KI-Nutzung sicher im Griff
KI schafft Effizienz, erhöht aber das Risiko unkontrollierten Datenabflusses — von HR und Finance bis zu IP.
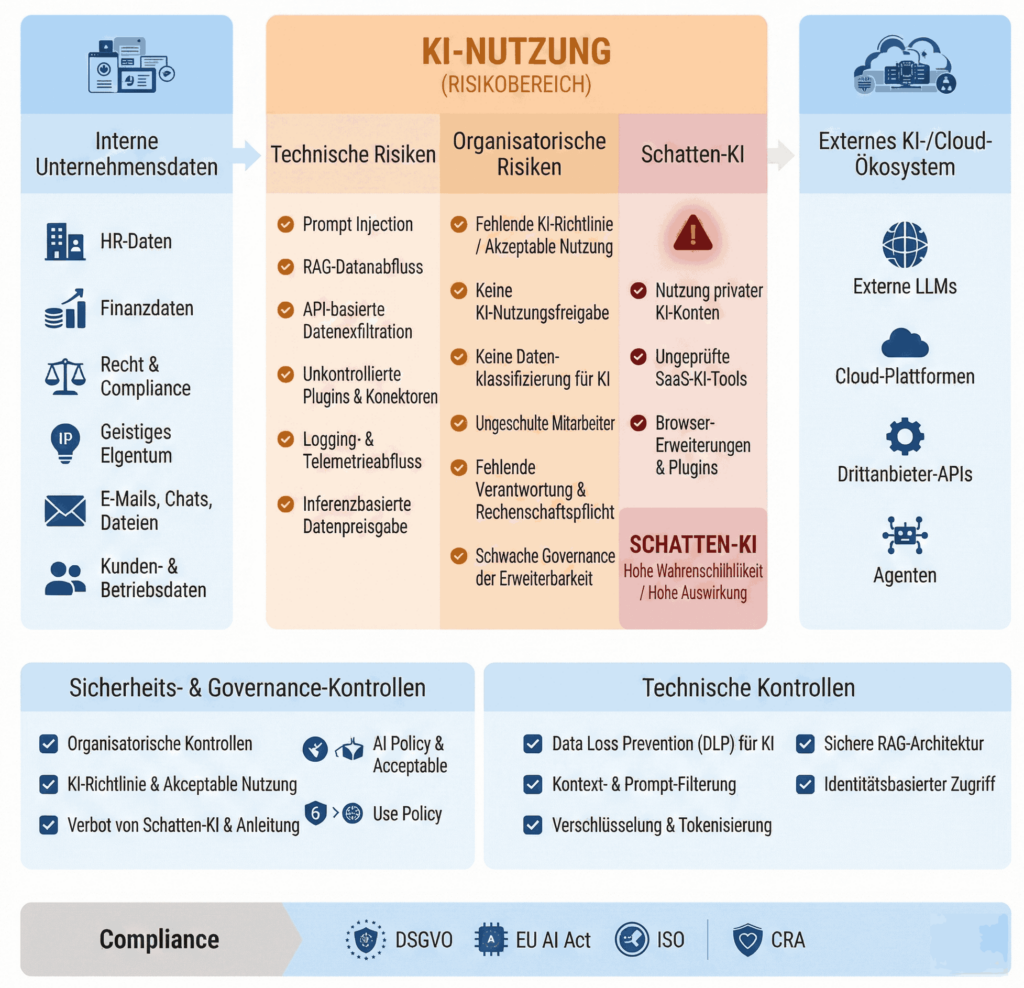
Erhebung
Welche Daten landen freiwillig oder unbewusst im Kontext?
Verarbeitung
Wo werden Inhalte gespiegelt, gecacht oder weitergeleitet?
Exfiltration
Können Prompts oder Antworten sensible Felder rekonstruieren?
Kontrolle
DLP, Labels, Policy-Engines, Logging — messbar validieren.
Microsoft Copilot Risiken
Unterschiedliche Copilot-Varianten — unterschiedliche Datenflüsse und Kontrollbedarfe.
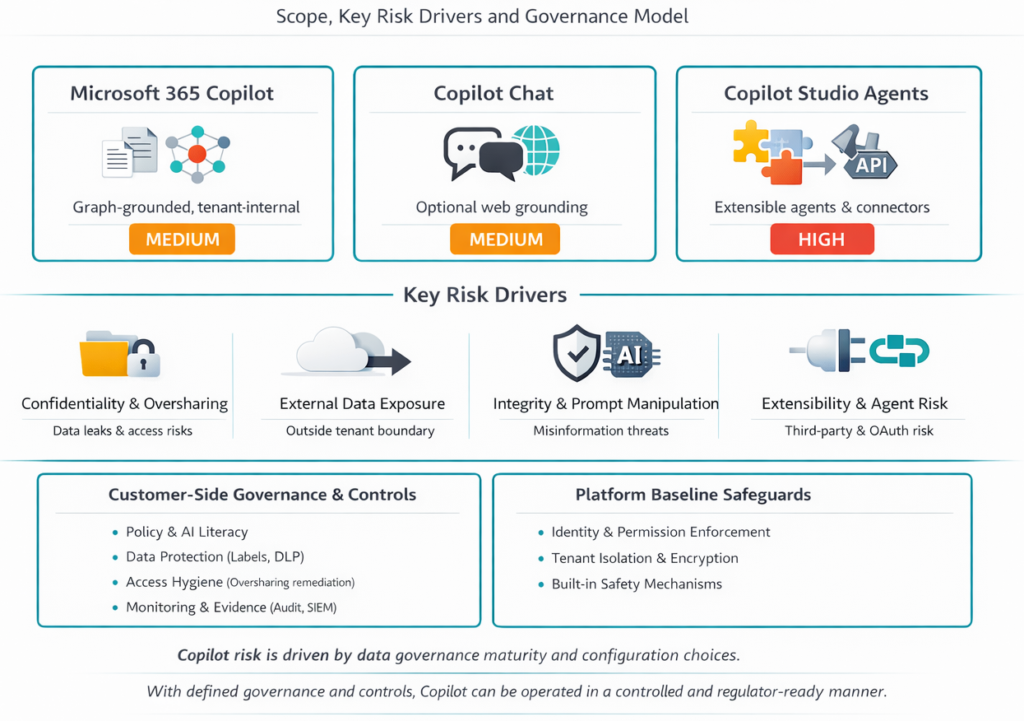
Microsoft 365 Copilot
Mittleres Risiko — Datenlecks, Zugriffskontrollen, Klassifizierung, Monitoring.
Copilot Chat
Erhöhtes Risiko durch Web-Integration: Datenabfluss, Prompt-Manipulation.
Copilot Studio Agents
Hohes Risiko — autonome Agents, OAuth, Drittanbieter ohne Risikomanagement.
Was Sie erhalten
Résultats priorisés par risque
Chemins d'attaque réels avec une priorisation claire par impact métier et risque.
Cas de test reproductibles
Cas de test traçables et techniquement reproductibles avec preuves de concept.
Mesures d'atténuation concrètes
Contrôles de sécurité clairs et mesures de remédiation pour l'ingénierie et la gouvernance.
Rapport pour la direction
Résumé exécutif de niveau managérial pour les audits, la conformité et les décideurs.
Tests de sécurité IA agentique
Nous simulons des scénarios d'exploitation ciblés contre les architectures d'IA agentiques : détournement d'outils, prise de contrôle des objectifs, fuites de mémoire, injection de prompts dans les workflows multi-agents et usurpation d'identité.
Conformité et réglementation
Les risques liés à l'IA ne sont pas une question future – ils surviennent en exploitation. Nos tests créent des preuves robustes pour l'EU AI Act, NIS2, DORA, le RGPD, ISO 27001 & ISO 42001.
Was wir testen
Que fait un test de pénétration IA & LLM ?
Model Discovery & Recon
Analyse de tous les endpoints IA, API et données de contexte pour rendre visible l'ensemble de la surface d'attaque.
Prompt Injection & Jailbreak
Simulation ciblée d'entrées capables d'amener les modèles à effectuer des actions non autorisées.
Attaques IA agentiques
Tests contre les agents autonomes, le contrôle des workflows et le chaînage de contexte.
Risques liés aux données et aux API
Détection de fuites de données, d'API non sécurisées et d'expositions de contexte sensible.
Du cadre à la mise en œuvre
D'abord comprendre, puis tester, puis gouverner, puis protéger durablement. Évaluer → Tester → Gouverner → Protéger.
OWASP AIVSS — Bewertung agentischer KI
CVSS allein reicht nicht — AIVSS kombiniert CVSS v4.0 mit AARS (Agentic Risk Score). Qualitative Entscheidungen: Defer, Scheduled, Out-of-Cycle, Immediate.
GenAI Red Teaming
Discover
Oberflächen, Modelle, Tools, Datenquellen kartieren.
Attack
Szenarien aus OWASP LLM/Agentic, custom Abuse Cases.
Measure
AIVSS, Repro-Schritte, Severity-Workshop.
Des systèmes d'IA sécurisés à une conformité auditable
Les vulnérabilités web classiques rencontrent des risques spécifiques à l'IA : prompt injection, empoisonnement de données et de modèles, chemins d'outils et de RAG non sécurisés. Nos pentests et revues alignées OWASP fournissent des preuves reproductibles — adaptées à ce que les autorités de surveillance et les audits attendent en matière de « robustesse », « cybersécurité » et gestion des risques.
Des obligations qui exigent une profondeur technique
Pour les systèmes d'IA à haut risque, les analyses de risque documentées et les mesures techniques efficaces sont obligatoires. Les conclusions de pentest étayent l'art. 15 (cybersécurité, robustesse) et renforcent la gestion des risques de l'art. 9. Les obligations de transparence et de données (art. 10, 13) peuvent être étayées par des preuves claires sur les flux de données, la journalisation et la chaîne d'approvisionnement du modèle.
- Art. 9 — système de gestion des risques : continu, documenté, lié à la classe de risque
- Art. 10 — données & gouvernance : qualité, surveillance des biais, données d'entraînement et d'exploitation représentatives
- Art. 15 — exactitude, robustesse, cybersécurité : simulations d'attaque ciblées et PoC concrets
Services critiques & exigences de preuve renforcées
Les composants d'IA dans les secteurs critiques et essentiels sont soumis à des exigences renforcées en matière de sécurité et de preuves. Audits de sécurité réguliers, gestion des vulnérabilités et artefacts de risque robustes font partie du standard attendu.
- Audits de sécurité réguliers de l'infrastructure d'IA
- Artefacts de risque démontrables pour les échanges avec les autorités
- Intégration dans les processus de réponse aux incidents NIS2
Système de management de l'IA (SMIA)
Le système de management de l'IA exige une sécurité opérationnelle et une évaluation continue. Les tests techniques (pentest, red team, scénarios LLM/agent ciblés) fournissent des entrées mesurables pour le contrôle, l'amélioration et les discussions de certification.
- Entrées mesurables pour le système de contrôle SMIA
- Combinable avec ISO 27001 pour des preuves partagées
- Base pour les discussions de certification et les audits
Secteur financier — traiter l'IA comme une IT productive
La surface d'attaque TIC croît avec chaque interface de chat, copilote et workflow autonome. DORA exige des tests systématiques de la résilience numérique ; du point de vue des autorités, les mêmes standards s'appliquent aux systèmes assistés par IA qu'à l'IT classique.
- Gestion des risques TIC y compris chaînes d'approvisionnement IA et externalisation
- Cycles de tests et de revues démontrables, pas seulement des mesures ponctuelles
- Conclusions documentables pour les échanges d'audit interne et de surveillance



Häufig gestellte Fragen
Protégez vos systèmes d'IA maintenant
Contactez-nous pour une évaluation de sécurité LLM sur mesure – pragmatique, prête pour l'audit et adaptée à vos exigences.
Erstberatung buchen