IA y LLM Penetration Testing
Simulaciones de ataque para sistemas de IA seguros y conformes con el AI Act — Prompt Injection, exfiltración de datos y exploits agénticos. Pentests reales de IA según estándares OWASP más conformidad para AI Act y NIS2.

OWASP Top 10 para Agentic Applications: Demo en vivo
Máquinas contra máquinas — Valeri Milke y Lucas Murtfeld muestran offensive y defensive en la era de la IA. Con live hack a Prompt Injection.
Securing Agentic AI con PyTorch: Threat Modeling & Red Teaming
En la PyTorch Conference Europe 2026, Valeri Milke muestra cómo el threat modeling MAESTRO y el OWASP LLM Top 10 se combinan para sistemas de agentic AI — con una demo en vivo de un ataque de prompt injection sobre un workflow agéntico.
Nota: La IA amplía la superficie de ataque más allá del software clásico — probar pronto reduce los riesgos de incidente, conformidad y auditoría.
Las organizaciones integran IA más rápido de lo que avanzan los controles de seguridad
El pentesting de IA crea una validación robusta antes de que las vulnerabilidades se conviertan en incidentes o hallazgos de auditoría. Visibilidad en operación, protección frente a riesgos de datos y alineamiento de conformidad con EU AI Act, NIS2 y audit-readiness.
- Nuevas clases de ataque: Prompt Injection, Data Poisoning, Model Extraction — sin precedente en seguridad clásica
- No deterministas: los LLMs no siguen una lógica fija — análisis estático y firmas no funcionan
- Superficie de ataque ampliada: training, inferencia, APIs, plugins, agents — cada fase es atacable
- Presión de conformidad: EU AI Act, NIS2, DORA y RGPD exigen medidas demostrables de seguridad de IA
- OWASP Top 10 for Agentic Applications 2026
- Mapeado a MITRE ATLAS, NIST AI RMF, EU AI Act ready, ISO 27001 / 42001
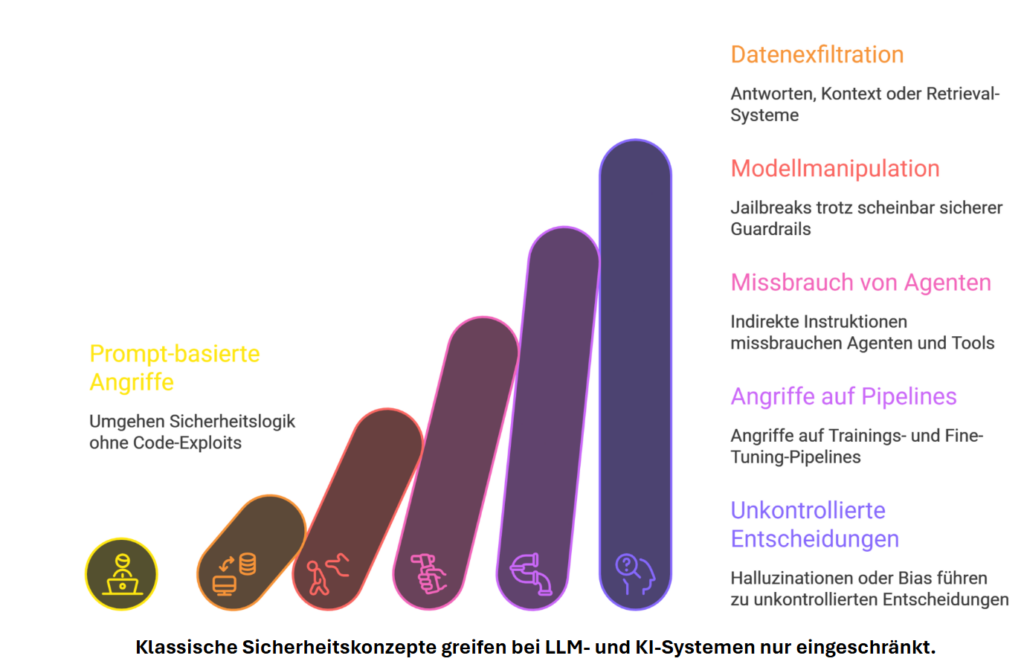
Seis niveles de amenaza de IA
Desde trucos sutiles de prompt hasta decisiones incontroladas — cada nivel escala el riesgo y socava conceptos de seguridad clásicos.
Amenazas de seguridad en IA y LLM
Visión de las amenazas y vulnerabilidades típicas en sistemas IA y LLM productivos — punto de partida para pentests estructurados.

Entrada
Prompt Injection, jailbreaks, documentos no confiables (PDF, adjuntos de correo).

Datos y contexto
Exfiltración, manipulación de RAG/embeddings, memory poisoning.

Cadena de suministro
Modelos, LoRA, plugins, APIs — integridad sobre el ciclo de vida.

Salida
Improper Output Handling, XSS/inyección en sistemas posteriores.

Agentic
Mal uso de herramientas, goal hijacking, permisos excesivos.

Operación
Unbounded Consumption, Shadow AI, falta de logging y aplicación de políticas.
Nuestra guía CISO sobre seguridad de IA y Red Teaming
Encuadre práctico para CISOs y security leads — desde el panorama de amenazas hasta enfoques concretos de prueba y gobernanza.
Contenido de un vistazo
Threat landscape para LLM y agents, metodología de pentest y red team, delimitación frente al AppSec clásico, checklists para gobernanza y conversaciones de auditoría.

Las empresas se enfrentan a desafíos estructurales de seguridad de IA
Las organizaciones integran IA y LLMs rápidamente — a menudo más rápido de lo que avanzan los controles de seguridad, riesgo y gobernanza.
No quedarse quieto — pero tampoco correr
Visibilidad en operación
Los riesgos de IA surgen en operación — los pentests los hacen visibles y controlables.
Negocio y remediación
Protección frente a riesgos de datos y de negocio; visión de seguridad realista y remediación concreta.
Regulación
Alineamiento de conformidad: EU AI Act, NIS2 y audit-readiness.
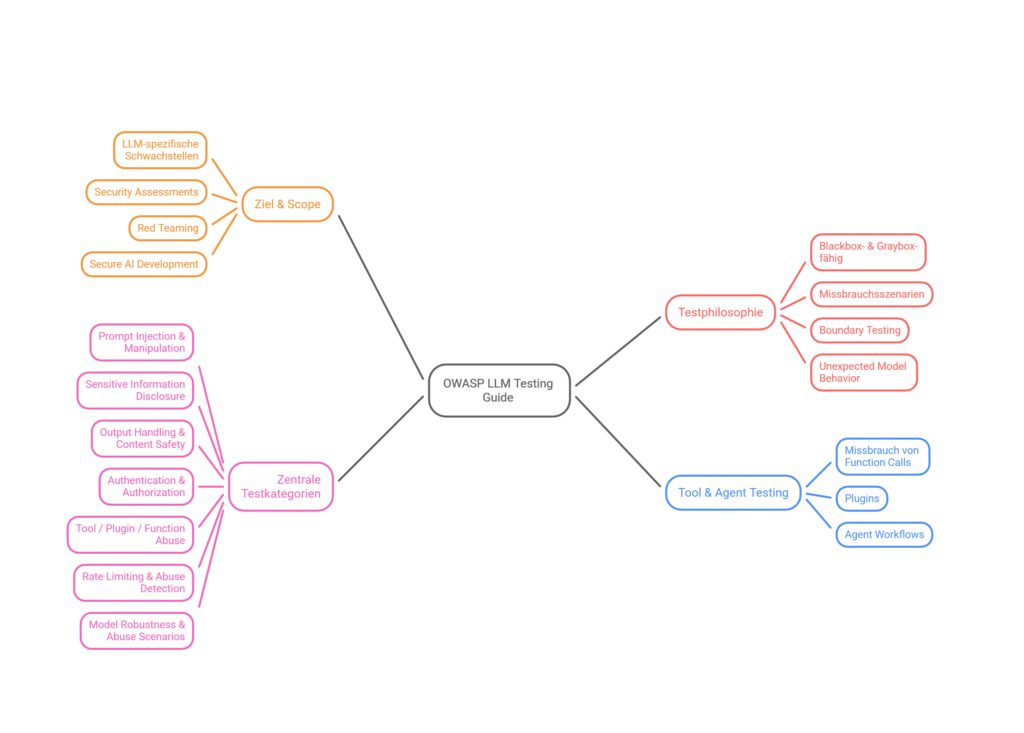
OWASP Top 10 for LLM Applications
Los 10 riesgos de seguridad más críticos para Large Language Models — base de nuestra metodología de pruebas.
Prompt Injection
Instrucciones maliciosas en entradas manipulan el modelo — ignorar reglas, divulgar datos o generar contenido dañino. Esto incluye injection directa e indirecta: instrucciones embebidas en correos, PDFs, páginas web o documentos RAG. Los filtros clásicos suelen fallar porque el ataque sucede en el contexto del lenguaje natural.
Sensitive Information Disclosure
Divulgación de datos confidenciales vía salidas o configuración — PII, secretos comerciales, datos internos del modelo. Especialmente arriesgado en sesiones largas, sin filtros de salida e indicaciones de sistema o desarrollador suministradas por error. Mitigación: minimizar contexto, eliminar patrones sensibles de logs.
Supply Chain
Modelos, datasets, librerías o plataformas comprometidos — integridad y confianza sobre el ciclo de vida de IA. Vulnerabilidades típicas: adapters sin firma, paquetes pip/npm en pipelines ML, APIs de terceros sin prueba de origen. Sin verificación de hash, versión y proveedor, la integridad en operación es difícilmente auditable.
Data & Model Poisoning
Manipulación de datos de training o fine-tuning — sesgo, backdoors, vulnerabilidades. Fuentes como crowdsourcing, web crawls o sets adversariales de fine-tuning pueden desplazar comportamiento sutilmente — hasta backdoors dependientes de trigger. Las pruebas apuntan a pipelines de datos, labeling e interfaces de re-training.
Improper Output Handling
Contenidos generados sin validación a sistemas posteriores — XSS, injections, divulgación de datos. Cualquier sistema que pase salida de modelo a SQL, shell, HTML o al navegador genera superficies de injection clásicas. Output encoding, tipado y allowlists siguen siendo obligatorios — el LLM no reemplaza la validación del lado del servidor.
Excessive Agency
Demasiada autonomía o permisos — acciones no intencionadas o dañinas. Causas frecuentes: scopes OAuth demasiado amplios, políticas genéricas «agente puede todo», falta de confirmación antes de transacciones. Verificamos qué herramientas son realmente necesarias y si el Human-in-the-Loop funciona.
System Prompt Leakage
Divulgación de prompts del sistema y lógicas internas de control — elusión de mecanismos de protección. A menudo combinación de preguntas dirigidas y leaks parciales vía formatos de salida. Recomendación: sin secretos en el prompt; mantener políticas y reglas externas y versionadas.
Vector & Embedding Weakness
Manipulación de retrieval y embeddings — respuestas falsas, fuga de datos, pérdida de control. Relevante: embeddings adversariales, poisoning del corpus, separación de namespace/tenant en bases de datos vectoriales. Los pentests incluyen consultas dirigidas y accesos de escritura a rutas de retrieval.
Misinformation
Salidas plausibles pero falsas — riesgos de seguridad, reputación y responsabilidad. Especialmente crítico cuando los usuarios incorporan respuestas sin verificación a contratos, decisiones de seguridad o conformidad. Grounding y obligaciones de citar fuentes reducen el riesgo; la formación y el proceso son parte de la defensa.
Unbounded Consumption
Inferencia incontrolada — DoS, «Denial of Wallet», robo de modelo o replicación del comportamiento. API keys sin cuotas, falta de rate limits y scraping automatizado pueden disparar costes o leer comportamiento del modelo de forma sistemática. Billing alerts, abuse detection y throttling son estándar.
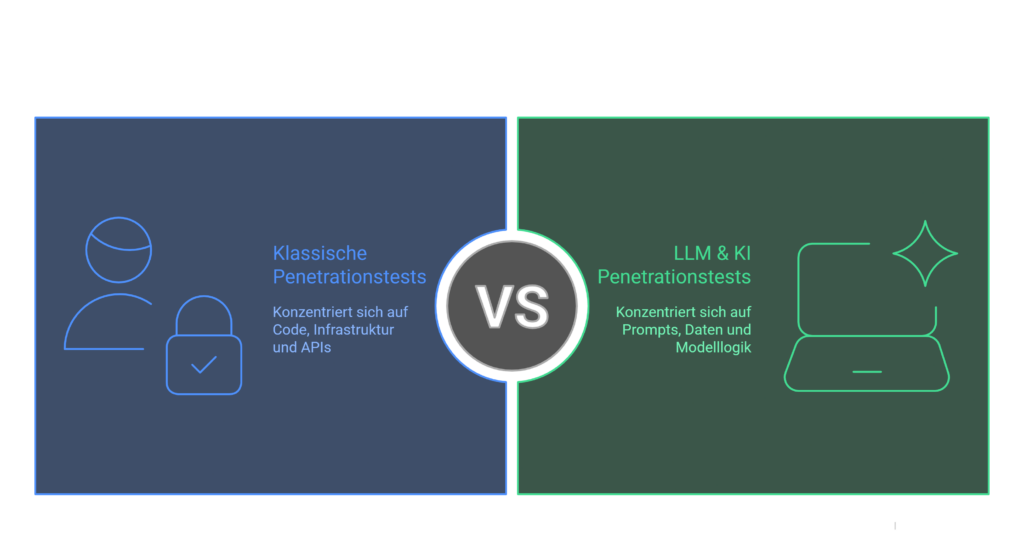
Comparación de seguridad de aplicaciones web e IA
La seguridad de aplicaciones sigue siendo el fundamento para NIS2 y AI Act — los LLMs amplían la superficie de ataque con prompts, datos de contexto y workflows agénticos.
- Injection, Broken Access Control, XSS, SSRF a nivel HTTP/API
- Sesiones stateful, validación del lado del servidor, patrones conocidos OWASP Web Top 10
- Foco: requests, responses, lógica del lado del servidor
- Prompt Injection, manipulación basada en contexto, jailbreaks
- RAG/embeddings, tool calling, cadenas multi-agente, exfiltración de datos
- Foco: ventana de contexto, políticas, decisiones agénticas
OWASP ASVS 5.0 reúne ~350 Security Requirements para aplicaciones. OWASP ASVS 5.0 — página completa →
AI Security Testing cercano a producción
Pentesting de IA con profundidad técnica — estructurado, reproducible y auditable para entornos productivos reales.
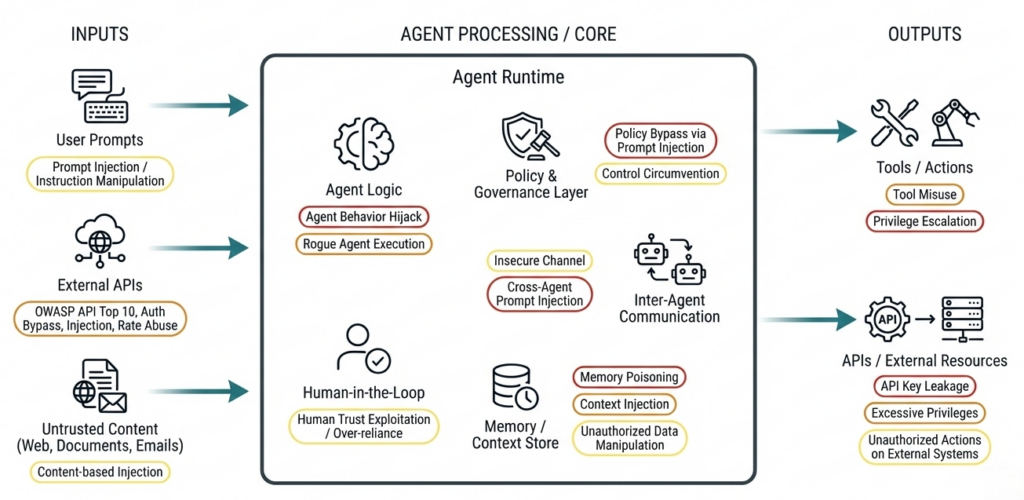
Agentic AI: más autonomía = más superficie de ataque
Los agentes autónomos ejecutan herramientas y mantienen contexto — riesgos que las pruebas de seguridad clásicas a menudo no cubren. Referencia: OWASP Top 10 for Agentic Applications (2026).
Ataques reales contra Agentic AI Systems
- Tool Misuse, Goal Hijacking y Memory Leaks
- Tool Selection y Context Chaining inseguros
- Identity Abuse (Human ↔ Agent)
- Prompt Injection en workflows multi-agente
- Model Confusion y riesgos de delegación
Verificamos sistemáticamente: qué acciones pueden ejecutar los agentes, cómo se vinculan los contextos entre agentes, herramientas y workflows, y cuán seguras son las decisiones, bucles y ejecuciones de herramientas.
Riesgos de seguridad y técnicos
Hijacking, Prompt Injection, exposición de datos — superficie de ataque ampliada.
Riesgos operativos y de control
Confianza excesiva sin Human-in-the-Loop puede costar control.
Negocio y conformidad
AI Act, RGPD — gestión estructurada del riesgo de IA.
Social y ético
Desinformación, deepfakes — Secure-by-Design y pruebas regulares.
AI y LLM Security CTF
Rutas de ataque típicas como Prompt Injection, mal uso de herramientas y agentes así como manejo inseguro de salida y datos — prácticamente comprensibles, realistas y aptas para empresa.
Prevenir fuga de datos: su uso de IA bajo control seguro
La IA crea eficiencia, pero aumenta el riesgo de fuga de datos no controlada — desde RR. HH. y Finanzas hasta IP.
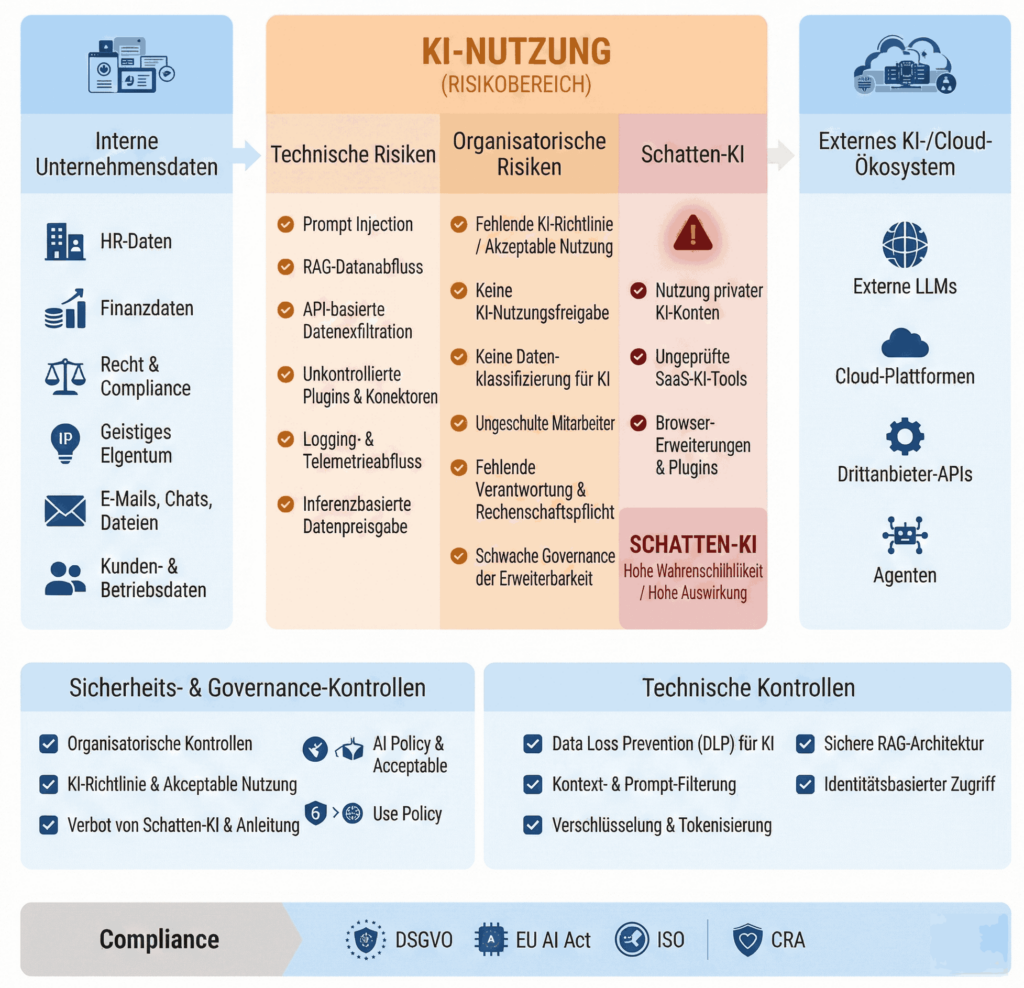
Captura
¿Qué datos llegan al contexto voluntaria o inconscientemente?
Procesamiento
¿Dónde se reflejan, cachean o reenvían los contenidos?
Exfiltración
¿Pueden los prompts o respuestas reconstruir campos sensibles?
Control
DLP, etiquetas, policy engines, logging — validar de forma medible.
Riesgos de Microsoft Copilot
Distintas variantes de Copilot — distintos flujos de datos y necesidades de control.
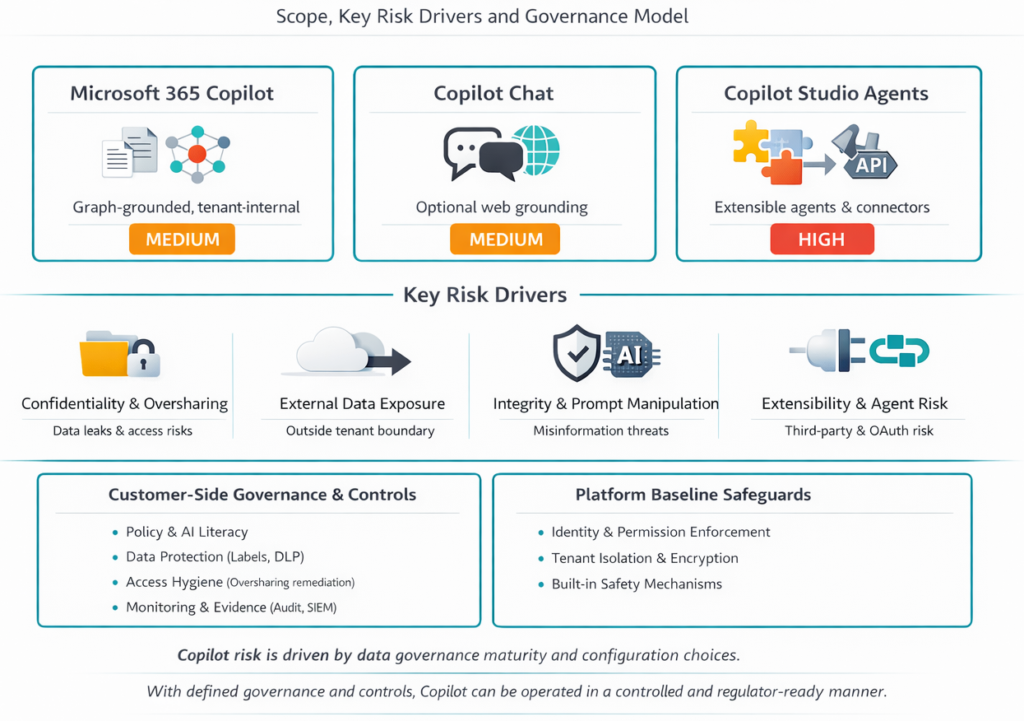
Microsoft 365 Copilot
Riesgo medio — fugas de datos, controles de acceso, clasificación, monitoreo.
Copilot Chat
Riesgo elevado por integración web: fuga de datos, manipulación de prompt.
Copilot Studio Agents
Riesgo alto — agentes autónomos, OAuth, terceros sin gestión de riesgos.
Lo que recibe
Risk-Prioritized Findings
Rutas de ataque reales con priorización clara por impacto de negocio y riesgo.
Reproducible Test Cases
Casos de prueba trazables, técnicamente reproducibles, y proof-of-concepts.
Concrete Mitigations
Controles de seguridad claros y medidas de remediación para Engineering y gobernanza.
Executive-Ready Reporting
Executive Summary apto para dirección, auditorías, conformidad y decisores.
Agentic AI Security Testing
Simulamos escenarios dirigidos de explotación contra arquitecturas de IA agéntica: Tool Misuse, Goal Hijacking, Memory Leaks, Prompt Injection en workflows multi-agente e Identity Abuse.
Conformidad y regulación
Los riesgos de IA no son una cuestión de futuro — surgen en operación. Nuestras pruebas crean evidencia robusta para EU AI Act, NIS2, DORA, RGPD, ISO 27001 e ISO 42001.
Lo que probamos
¿Qué hace un pentest de IA y LLM?
Model Discovery y Recon
Análisis de todos los endpoints de IA, APIs y datos de contexto para hacer visible la superficie de ataque completa.
Prompt Injection y Jailbreak
Simulación dirigida de entradas que pueden inducir a los modelos a acciones no autorizadas.
Ataques de IA agéntica
Pruebas contra agentes autónomos, dirección de workflows y encadenamiento de contexto.
Riesgos de datos y API
Detección de fugas de datos, APIs no aseguradas y liberaciones sensibles de contexto.
Del framework a la implementación
Primero entender, luego probar, luego regular, luego proteger de forma duradera. Assess → Test → Govern → Protect.
OWASP AIVSS — evaluación de IA agéntica
CVSS por sí solo no es suficiente — AIVSS combina CVSS v4.0 con AARS (Agentic Risk Score). Decisiones cualitativas: Defer, Scheduled, Out-of-Cycle, Immediate.
GenAI Red Teaming
Discover
Mapear superficies, modelos, herramientas, fuentes de datos.
Attack
Escenarios de OWASP LLM/Agentic, casos de abuso a medida.
Measure
AIVSS, pasos de reproducción, workshop de severity.
De sistemas de IA seguros a conformidad apta para auditoría
Las vulnerabilidades web clásicas se encuentran con riesgos específicos de IA: Prompt Injection, Data y Model Poisoning, rutas de herramientas y RAG inseguras. Nuestros pentests y revisiones orientadas a OWASP entregan evidencia reproducible — adecuada a lo que las conversaciones con supervisión y auditoría esperan bajo «robustez», «cybersecurity» y gestión de riesgos.
Obligaciones que requieren profundidad técnica
Para sistemas de IA de alto riesgo, los análisis de riesgo documentados y las medidas técnicas eficaces son obligatorios. Los hallazgos de pentest sustentan el Art. 15 (cybersecurity, robustez) y refuerzan la gestión de riesgos según el Art. 9. Las obligaciones de transparencia y datos (Art. 10, 13) se sustentan con evidencia clara sobre flujos de datos, logging y cadena de suministro del modelo.
- Art. 9 — sistema de gestión de riesgos: continuo, documentado, vinculado a la clase de riesgo
- Art. 10 — datos y gobernanza: calidad, monitoreo de sesgo, datos representativos de training y operación
- Art. 15 — accuracy, robustness, cybersecurity: simulaciones de ataque dirigidas y PoCs duros
Servicios críticos y obligaciones reforzadas de evidencia
Los componentes de IA en áreas críticas y esenciales están sujetos a obligaciones reforzadas de seguridad y evidencia. Las verificaciones regulares de seguridad, el manejo de vulnerabilidades y los artefactos de riesgo robustos son parte del horizonte de expectativa.
- Verificaciones regulares de seguridad de la infraestructura IA
- Artefactos de riesgo demostrables para conversaciones con supervisión
- Integración en procesos NIS2 de Incident Response
Sistema de gestión de IA (AIMS)
El sistema de gestión de IA exige seguridad operativa y evaluación continua. Las pruebas técnicas (pentest, Red Team, escenarios LLM/Agent dirigidos) entregan inputs medibles para control, mejora y conversaciones de certificación.
- Inputs medibles para el sistema de control AIMS
- Combinable con ISO 27001 para evidencias compartidas
- Base para conversaciones de certificación y auditorías
Sector financiero — tratar la IA como TI productiva
La superficie de ataque TIC crece con cada interfaz de chat, copilot y workflow autónomo. DORA exige pruebas sistemáticas de la resiliencia digital; desde la perspectiva de supervisión, los sistemas asistidos por IA están sujetos a los mismos estándares que la TI clásica.
- Gestión de riesgos TIC incl. cadenas de suministro IA y outsourcing
- Ciclos de prueba y revisión demostrables, no solo medidas puntuales
- Hallazgos documentables para conversaciones de auditoría interna y supervisión



Preguntas frecuentes
Proteja sus sistemas de IA ahora
Contáctenos para un LLM Security Assessment individual — orientado a la práctica, audit-ready y adaptado a sus requisitos.
Reservar consulta inicial