KI & LLM Penetration Testing
Angriffssimulationen für sichere und AI-Act-konforme KI-Systeme — Prompt Injection, Datenexfiltration und agentische Exploits. Reale KI-Pentests nach OWASP-Standards plus Compliance für AI Act & NIS2.

OWASP Top 10 für Agentic Applications: Live Demo
Maschinen gegen Maschinen — Valeri Milke und Lucas Murtfeld zeigen Offensive und Defensive in der Ära der KI. Mit Live-Hack zu Prompt Injection.
Hinweis: KI erweitert die Angriffsfläche über klassische Software hinaus — früh testen reduziert Incident-, Compliance- und Audit-Risiken.
Organisationen integrieren KI schneller als Sicherheitskontrollen nachziehen
KI-Pentesting schafft belastbare Validierung, bevor Schwachstellen zu Incidents oder Audit-Findings werden. Sichtbarkeit im Betrieb, Schutz vor Datenrisiken und Compliance-Alignment mit EU AI Act, NIS2 und Audit-Readiness.
- Neue Angriffsklassen: Prompt Injection, Data Poisoning, Model Extraction — ohne Precedent in klassischer Security
- Nicht deterministisch: LLMs folgen keiner festen Logik — statische Analyse und Signaturen greifen nicht
- Erweiterte Angriffsfläche: Training, Inference, APIs, Plugins, Agents — jede Phase ist angreifbar
- Compliance-Druck: EU AI Act, NIS2, DORA und GDPR fordern nachweisbare KI-Sicherheitsmaßnahmen
- OWASP Top 10 for Agentic Applications 2026
- MITRE ATLAS mapped, NIST AI RMF, EU AI Act ready, ISO 27001 / 42001
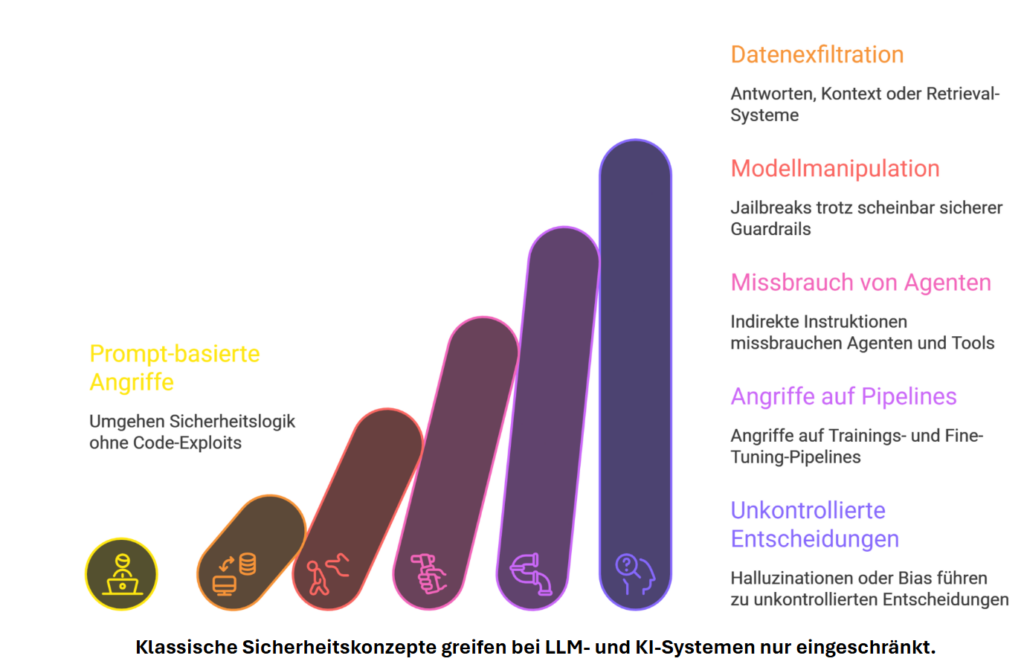
Sechs Stufen der KI-Bedrohung
Von subtilen Prompt-Tricks bis zu unkontrollierten Entscheidungen — jede Stufe eskaliert das Risiko und unterwandert klassische Sicherheitskonzepte.
Sicherheitsbedrohungen bei AI & LLM
Überblick über typische Bedrohungen und Schwachstellen in produktiven KI- und LLM-Systemen — Ausgangspunkt für strukturierte Pentests.

Eingabe
Prompt Injection, Jailbreaks, untrusted Documents (PDF, E-Mail-Anhänge).

Daten & Kontext
Exfiltration, RAG/Embedding-Manipulation, Memory Poisoning.

Supply Chain
Modelle, LoRA, Plugins, APIs — Integrität über den Lebenszyklus.

Output
Improper Output Handling, XSS/Injektion in nachgelagerte Systeme.

Agentic
Tool-Missbrauch, Goal Hijacking, übermäßige Berechtigungen.

Betrieb
Unbounded Consumption, Shadow AI, fehlende Logging/Policy-Durchsetzung.
Unser CISO-Leitfaden zur KI-Sicherheit und Red Teaming
Praxisnahe Einordnung für CISOs und Security-Leads — von Bedrohungslandschaft bis zu konkreten Test- und Governance-Ansätzen.
Inhalt auf einen Blick
Threat Landscape für LLM & Agents, Pentest- und Red-Team-Methodik, Abgrenzung zu klassischer AppSec, Checklisten für Governance und Audit-Gespräche.

Unternehmen stehen vor strukturellen KI-Sicherheitsherausforderungen
Organisationen integrieren KI und LLMs rasant — oft schneller, als Sicherheits-, Risiko- und Governance-Kontrollen nachziehen.
Nicht stehen bleiben — aber auch nicht rasen
Sichtbarkeit im Betrieb
KI-Risiken entstehen im laufenden Betrieb — Pentests machen sie sichtbar und beherrschbar.
Business & Remediation
Schutz vor Daten- und Geschäftsrisiken; realitätsnahes Sicherheitsbild und konkrete Remediation.
Regulatorik
Compliance-Alignment: EU AI Act, NIS2 und Audit-Readiness.
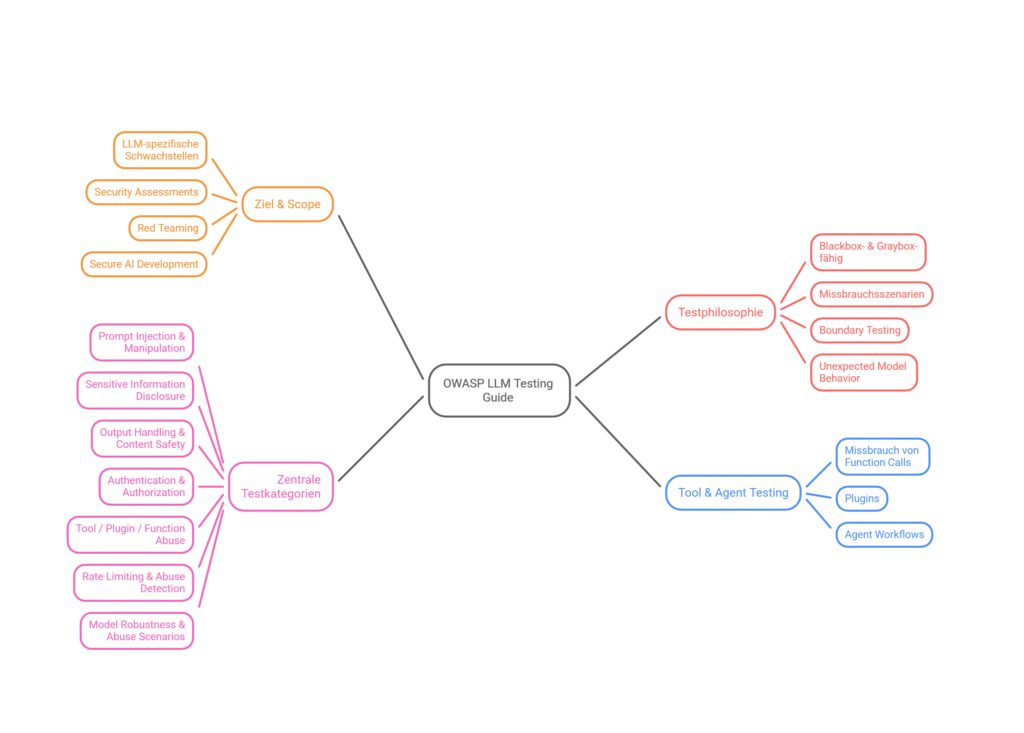
OWASP Top 10 for LLM Applications
Die 10 kritischsten Sicherheitsrisiken für Large Language Models — Grundlage unserer Testmethodik.
Prompt Injection
Bösartige Anweisungen in Eingaben manipulieren das Modell — Regeln ignorieren, Daten preisgeben oder schädliche Inhalte erzeugen. Dazu zählen direkte und indirekte Injection: eingebettete Anweisungen in E-Mails, PDFs, Webseiten oder RAG-Dokumenten. Klassische Filter versagen oft, weil der Angriff im natürlichen Sprachkontext stattfindet.
Sensitive Information Disclosure
Offenlegung vertraulicher Daten über Ausgaben oder Konfiguration — PII, Geschäftsgeheimnisse, interne Modelldaten. Besonders riskant bei langen Sessions, fehlenden Output-Filtern und versehentlich mitgelieferten System- oder Entwicklerhinweisen. Mitigation: Kontext minimieren, sensitive Muster aus Logs verbannen.
Supply Chain
Kompromittierte Modelle, Datensätze, Bibliotheken oder Plattformen — Integrität und Vertrauen über den KI-Lebenszyklus. Typische Schwachstellen: unsignierte Adapter, pip/npm-Pakete in ML-Pipelines, Drittanbieter-APIs ohne Herkunftsnachweis. Ohne Hash-, Versions- und Lieferantenprüfung ist Integrität im Betrieb schwer auditierbar.
Data & Model Poisoning
Manipulation von Trainings- oder Fine-Tuning-Daten — Bias, Hintertüren, Schwachstellen. Quellen wie Crowdsourcing, Web-Crawls oder feindliche Fine-Tuning-Sets können Verhalten subtil verschieben — bis zu triggernabhängigen Backdoors. Tests zielen auf Datenpipelines, Labeling und Re-Training-Schnittstellen.
Improper Output Handling
Generierte Inhalte ohne Validierung an nachgelagerte Systeme — XSS, Injektionen, Datenoffenlegung. Jedes System, das Modellausgabe in SQL, Shell, HTML oder an den Browser weitergibt, erzeugt klassische Injection-Flächen. Output-Encoding, Typisierung und Allowlists bleiben Pflicht — das LLM ersetzt keine serverseitige Validierung.
Excessive Agency
Zu viel Autonomie oder Berechtigung — unbeabsichtigte oder schädliche Aktionen. Häufige Ursachen: zu breite OAuth-Scopes, generische "Agent darf alles"-Policies, fehlende Bestätigung vor Transaktionen. Wir prüfen, welche Tools wirklich nötig sind und ob Human-in-the-Loop greift.
System Prompt Leakage
Offenlegung von System-Prompts und internen Steuerlogiken — Umgehung von Schutzmechanismen. Oft Kombination aus gezielten Fragen und teilweisen Leaks über Ausgabeformate. Empfehlung: keine Secrets im Prompt; Policies und Regeln extern und versioniert halten.
Vector & Embedding Weakness
Manipulation von Retrieval und Embeddings — falsche Antworten, Datenabfluss, Kontrollverlust. Relevant: adversariale Embeddings, Poisoning des Korpus, Namespace-/Tenant-Trennung in Vektordatenbanken. Pentests umfassen gezielte Abfragen und Schreibzugriffe auf Retrieval-Pfade.
Misinformation
Plausible, aber falsche Ausgaben — Sicherheits-, Reputations- und Haftungsrisiken. Besonders kritisch, wenn Nutzer Antworten ohne Prüfung in Verträge, Security- oder Compliance-Entscheidungen übernehmen. Grounding und Quellenpflichten reduzieren das Risiko; Schulung und Prozess sind Teil der Abwehr.
Unbounded Consumption
Unkontrollierte Inferenz — DoS, "Denial of Wallet", Modell-Diebstahl oder Replikation des Verhaltens. API-Keys ohne Quoten, fehlende Rate-Limits und automatisiertes Scraping können Kosten explodieren lassen oder Modellverhalten systematisch auslesen. Billing-Alerts, Abuse-Detection und Throttling gehören zum Standard.
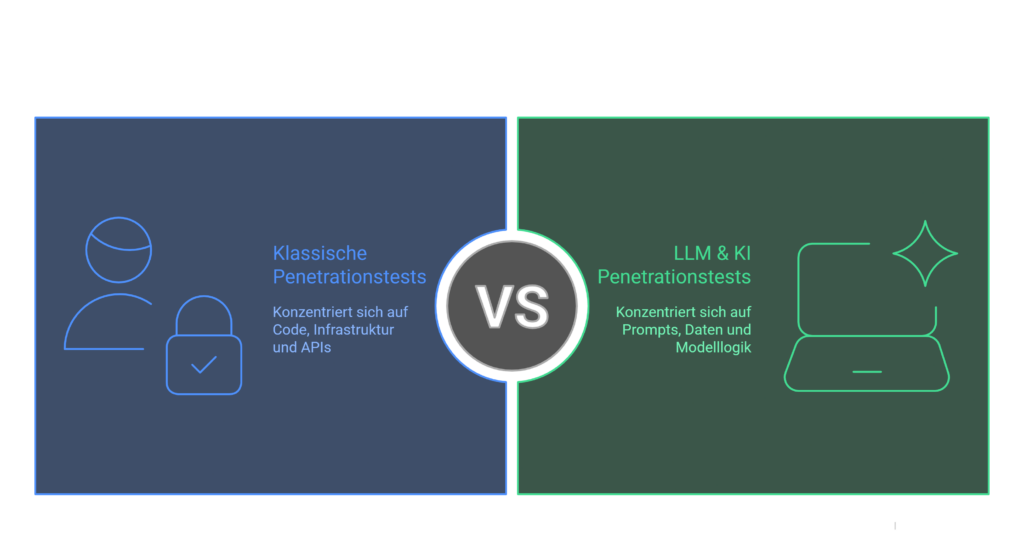
Vergleich von Web- und KI-Anwendungssicherheit
Applikationssicherheit bleibt das Fundament für NIS2 und AI Act — LLMs erweitern die Angriffsfläche um Prompts, Kontextdaten und agentische Workflows.
- Injection, Broken Access Control, XSS, SSRF auf HTTP/API-Ebene
- Stateful Sessions, serverseitige Validierung, bekannte OWASP-Web-Top-10-Muster
- Fokus: Requests, Responses, serverseitige Logik
- Prompt Injection, kontextbasierte Manipulation, Jailbreaks
- RAG/Embeddings, Tool-Calling, Multi-Agent-Ketten, Datenexfiltration
- Fokus: Kontextfenster, Policies, agentische Entscheidungen
OWASP ASVS 5.0 bündelt ~350 Security Requirements für Anwendungen. OWASP ASVS 5.0 — vollständige Seite →
Produktionsnahes KI-Security-Testing
KI-Pentesting mit technischer Tiefe — strukturiert, reproduzierbar und auditfähig für reale Produktionsumgebungen.
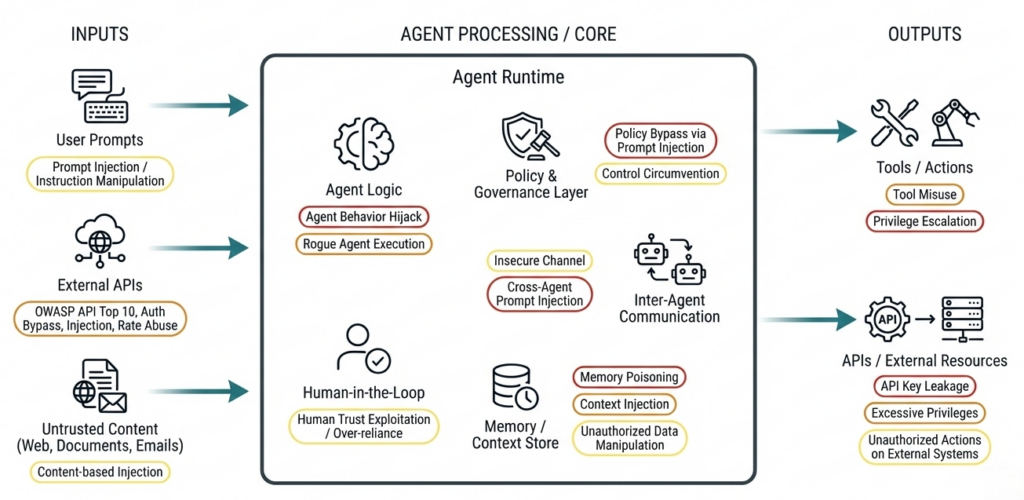
Agentic AI: mehr Autonomie = mehr Angriffsfläche
Autonome Agents führen Tools aus und behalten Kontext — Risiken, die klassische Security-Tests oft nicht abdecken. Referenz: OWASP Top 10 for Agentic Applications (2026).
Reale Angriffe auf Agentic AI Systems
- Tool Misuse, Goal Hijacking & Memory Leaks
- Unsichere Tool Selection & Context Chaining
- Identity Abuse (Human ↔ Agent)
- Prompt Injection in Multi-Agent Workflows
- Model Confusion & Delegation Risks
Wir prüfen systematisch: welche Aktionen Agents ausführen dürfen, wie Kontexte zwischen Agents, Tools und Workflows verknüpft sind, und wie sicher Entscheidungen, Schleifen und Tool-Ausführungen sind.
Sicherheits- & technische Risiken
Hijacking, Prompt Injection, Datenexposition — erweiterte Angriffsfläche.
Betriebs- & Kontrollrisiken
Übermäßiges Vertrauen ohne Human-in-the-Loop kann Kontrolle kosten.
Business- & Compliance
AI Act, GDPR — strukturiertes KI-Risikomanagement.
Gesellschaftlich & ethisch
Desinformation, Deepfakes — Secure-by-Design und regelmäßige Tests.
AI & LLM Security CTF
Typische Angriffspfade wie Prompt Injection, Tool- und Agent-Missbrauch sowie unsichere Ausgabe- und Datenverarbeitung — praktisch nachvollziehbar, realistisch und enterprise-tauglich.
Datenabfluss verhindern: Ihre KI-Nutzung sicher im Griff
KI schafft Effizienz, erhöht aber das Risiko unkontrollierten Datenabflusses — von HR und Finance bis zu IP.
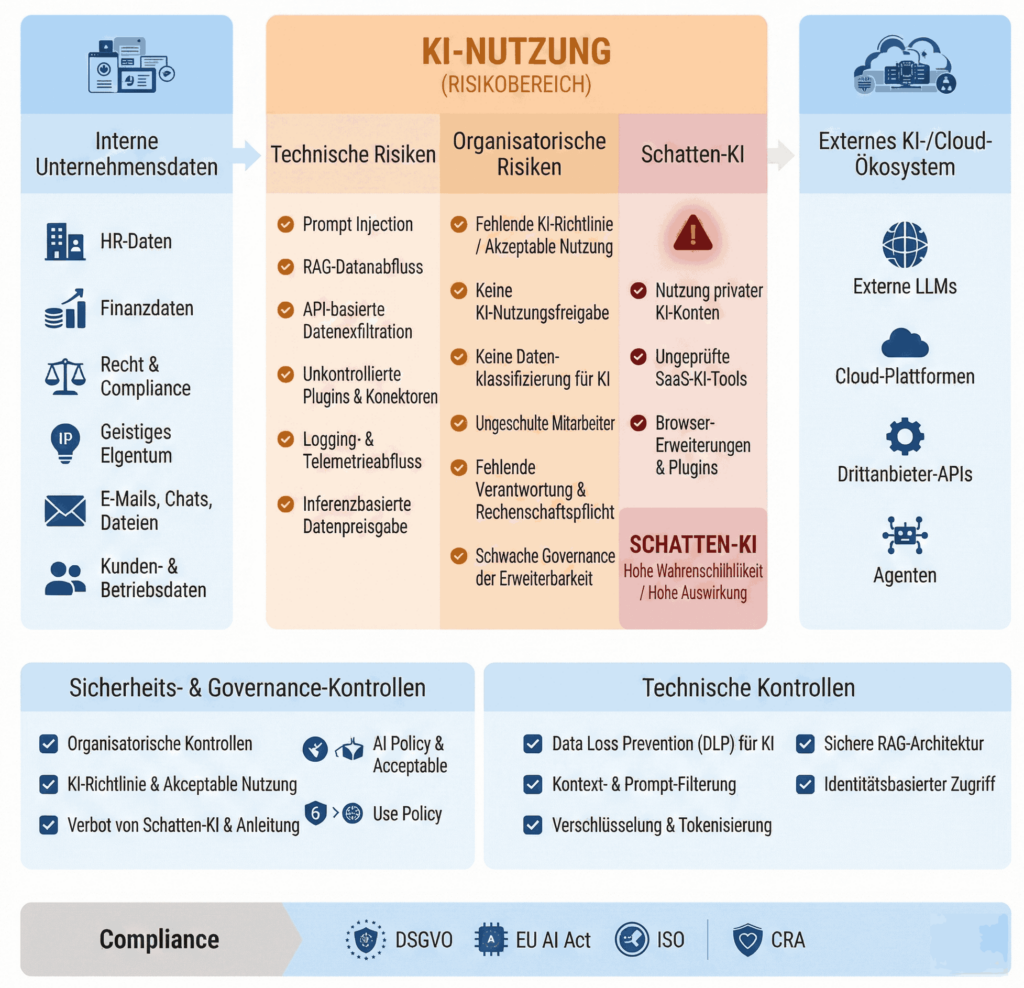
Erhebung
Welche Daten landen freiwillig oder unbewusst im Kontext?
Verarbeitung
Wo werden Inhalte gespiegelt, gecacht oder weitergeleitet?
Exfiltration
Können Prompts oder Antworten sensible Felder rekonstruieren?
Kontrolle
DLP, Labels, Policy-Engines, Logging — messbar validieren.
Microsoft Copilot Risiken
Unterschiedliche Copilot-Varianten — unterschiedliche Datenflüsse und Kontrollbedarfe.
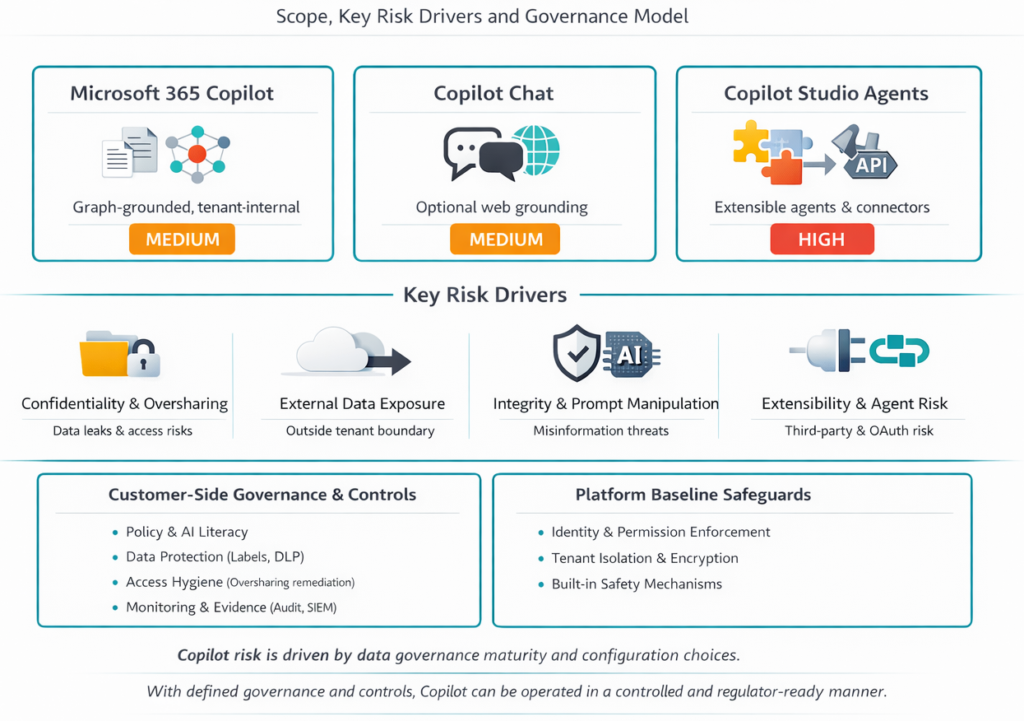
Microsoft 365 Copilot
Mittleres Risiko — Datenlecks, Zugriffskontrollen, Klassifizierung, Monitoring.
Copilot Chat
Erhöhtes Risiko durch Web-Integration: Datenabfluss, Prompt-Manipulation.
Copilot Studio Agents
Hohes Risiko — autonome Agents, OAuth, Drittanbieter ohne Risikomanagement.
Was Sie erhalten
Risk-Prioritized Findings
Reale Angriffspfade mit klarer Priorisierung nach Business Impact und Risiko.
Reproducible Test Cases
Nachvollziehbare, technisch reproduzierbare Testfälle und Proof-of-Concepts.
Concrete Mitigations
Klare Security Controls und Remediation-Maßnahmen für Engineering & Governance.
Executive-Ready Reporting
Management-taugliche Executive Summary für Audits, Compliance und Entscheider.
Agentic AI Security Testing
Wir simulieren gezielte Exploitation-Szenarien gegen agentische KI-Architekturen: Tool Misuse, Goal Hijacking, Memory Leaks, Prompt Injection in Multi-Agent Workflows und Identity Abuse.
Compliance & Regulatorik
KI-Risiken sind keine Zukunftsfrage — sie entstehen im laufenden Betrieb. Unsere Tests schaffen belastbare Nachweise für EU AI Act, NIS2, DORA, DSGVO, ISO 27001 & ISO 42001.
Was wir testen
Was macht ein KI & LLM Pentest?
Model Discovery & Recon
Analyse aller KI-Endpunkte, APIs und Kontextdaten, um die gesamte Angriffsfläche sichtbar zu machen.
Prompt Injection & Jailbreak
Gezielte Simulation von Eingaben, die Modelle zu unautorisierten Aktionen verleiten können.
Agentische KI-Angriffe
Tests gegen autonome Agenten, Workflow-Steuerung und Kontextverkettung.
Daten- & API-Risiken
Erkennung von Datenlecks, ungesicherten APIs und sensiblen Kontextfreigaben.
Vom Framework zur Umsetzung
Erst verstehen, dann testen, dann regeln, dann dauerhaft schützen. Assess → Test → Govern → Protect.
OWASP AIVSS — Bewertung agentischer KI
CVSS allein reicht nicht — AIVSS kombiniert CVSS v4.0 mit AARS (Agentic Risk Score). Qualitative Entscheidungen: Defer, Scheduled, Out-of-Cycle, Immediate.
GenAI Red Teaming
Discover
Oberflächen, Modelle, Tools, Datenquellen kartieren.
Attack
Szenarien aus OWASP LLM/Agentic, custom Abuse Cases.
Measure
AIVSS, Repro-Schritte, Severity-Workshop.
Von sicheren KI-Systemen zu auditfähiger Compliance
Klassische Web-Schwachstellen treffen auf KI-spezifische Risiken: Prompt Injection, Data & Model Poisoning, unsichere Tool- und RAG-Pfade. Unsere Pentests und OWASP-orientierten Reviews liefern reproduzierbare Evidenz — passend zu dem, was Aufsichts- und Auditgespräche unter "Robustheit", "Cybersecurity" und Risikomanagement erwarten.
Pflichten, die technische Tiefe verlangen
Für hochriskante KI-Systeme sind dokumentierte Risikoanalysen und wirksame technische Maßnahmen Pflicht. Pentest-Befunde untermauern Art. 15 (Cybersecurity, Robustheit) und stärken das Risikomanagement nach Art. 9. Transparenz- und Datenpflichten (Art. 10, 13) lassen sich mit klaren Nachweisen zu Datenflüssen, Logging und Modell-Lieferkette untermauern.
- Art. 9 — Risikomanagementsystem: fortlaufend, dokumentiert, an die Risikoklasse gekoppelt
- Art. 10 — Daten & Governance: Qualität, Bias-Monitoring, repräsentative Trainings- und Betriebsdaten
- Art. 15 — Accuracy, Robustness, Cybersecurity: gezielte Angriffssimulationen und harte PoCs
Kritische Dienste & verschärfte Nachweispflichten
KI-Komponenten in kritischen und wesentlichen Bereichen unterliegen verschärften Sicherheits- und Nachweispflichten. Regelmäßige Sicherheitsprüfungen, Umgang mit Schwachstellen und belastbare Risikoartefakte sind Teil des Erwartungshorizonts.
- Regelmäßige Sicherheitsprüfungen der KI-Infrastruktur
- Nachweisbare Risikoartefakte für Aufsichtsgespräche
- Integration in NIS2-Incident-Response-Prozesse
KI-Managementsystem (KIMS)
Das KI-Management-System verlangt operative Sicherheit und fortlaufende Bewertung. Technische Tests (Pentest, Red Team, gezielte LLM-/Agent-Scenarios) liefern messbare Inputs für Kontrolle, Verbesserung und Zertifizierungsgespräche.
- Messbare Inputs für das KIMS-Kontrollsystem
- Kombinierbar mit ISO 27001 für geteilte Evidenzen
- Grundlage für Zertifizierungsgespräche und Audits
Finanzsektor — KI wie produktive IT behandeln
IKT-Angriffsfläche wächst mit jedem Chat-Interface, Copilot und autonomen Workflow. DORA verlangt systematische Tests der digitalen Resilienz; aus Aufsichtssicht gelten für KI-gestützte Systeme dieselben Maßstäbe wie für klassische IT.
- IKT-Risikomanagement inkl. KI-Lieferketten und Outsourcing
- Nachweisbare Test- und Review-Zyklen, nicht nur Punktmaßnahmen
- Dokumentierbare Befunde für interne Audit- und Aufsichtsgespräche



Häufig gestellte Fragen
Schützen Sie Ihre KI-Systeme jetzt
Kontaktieren Sie uns für ein individuelles LLM Security Assessment — praxisnah, audit-ready und auf Ihre Anforderungen abgestimmt.
Erstberatung buchen