AI & LLM Penetration Testing – Attack Simulations for Secure and AI Act-Compliant AI Systems
Sustainably secure your AI systems and LLMs against attacks such as prompt injection, data exfiltration, and agentic exploits. Real-world AI pentests per OWASP standards + compliance for AI Act & NIS2.

OWASP Top 10 für Agentic Applications: Live Demo
Maschinen gegen Maschinen — Valeri Milke und Lucas Murtfeld zeigen Offensive und Defensive in der Ära der KI. Mit Live-Hack zu Prompt Injection.
Hinweis: KI erweitert die Angriffsfläche über klassische Software hinaus — früh testen reduziert Incident-, Compliance- und Audit-Risiken.
AI Pentesting is Essential
AI fundamentally expands the attack surface beyond traditional software. Prompts, context data, data pipelines, and agentic logic become independent risk points.
- New attack classes: Prompt Injection, Data Poisoning, Model Extraction – without precedent in traditional security
- Non-deterministic: LLMs follow no fixed logic – static analysis and signatures do not apply
- Expanded attack surface: Training, inference, APIs, plugins, agents – every phase is attackable
- Compliance pressure: EU AI Act, NIS2, DORA, and GDPR require demonstrable AI security measures
- OWASP Top 10 for Agentic Applications 2026
- MITRE ATLAS mapped, NIST AI RMF, EU AI Act ready, ISO 27001 / 42001
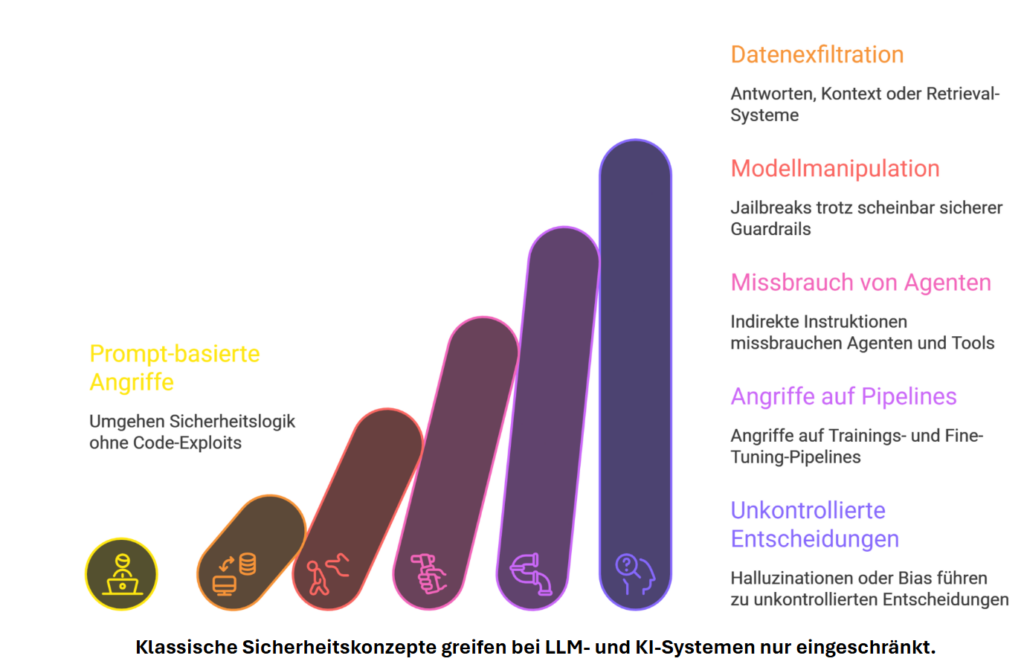
Six Stages of AI Threats
From subtle prompt tricks to uncontrolled decisions — each stage escalates risk and undermines classic security concepts.
Security threats in AI & LLM
Overview of typical threats and vulnerabilities in productive AI and LLM systems — the starting point for structured pentests.

Input
Prompt injection, jailbreaks, untrusted documents (PDFs, email attachments).

Data & context
Exfiltration, RAG/embedding manipulation, memory poisoning.

Supply chain
Models, LoRA, plugins, APIs — integrity across the lifecycle.

Output
Improper output handling, XSS / injection into downstream systems.

Agentic
Tool misuse, goal hijacking, excessive permissions.

Operations
Unbounded consumption, shadow AI, missing logging / policy enforcement.
Unser CISO-Leitfaden zur KI-Sicherheit und Red Teaming
Praxisnahe Einordnung für CISOs und Security-Leads — von Bedrohungslandschaft bis zu konkreten Test- und Governance-Ansätzen.
Inhalt auf einen Blick
Threat Landscape für LLM & Agents, Pentest- und Red-Team-Methodik, Abgrenzung zu klassischer AppSec, Checklisten für Governance und Audit-Gespräche.

Unternehmen stehen vor strukturellen KI-Sicherheitsherausforderungen
Organisationen integrieren KI und LLMs rasant — oft schneller, als Sicherheits-, Risiko- und Governance-Kontrollen nachziehen.
Nicht stehen bleiben — aber auch nicht rasen
Sichtbarkeit im Betrieb
KI-Risiken entstehen im laufenden Betrieb — Pentests machen sie sichtbar und beherrschbar.
Business & Remediation
Schutz vor Daten- und Geschäftsrisiken; realitätsnahes Sicherheitsbild und konkrete Remediation.
Regulatorik
Compliance-Alignment: EU AI Act, NIS2 und Audit-Readiness.
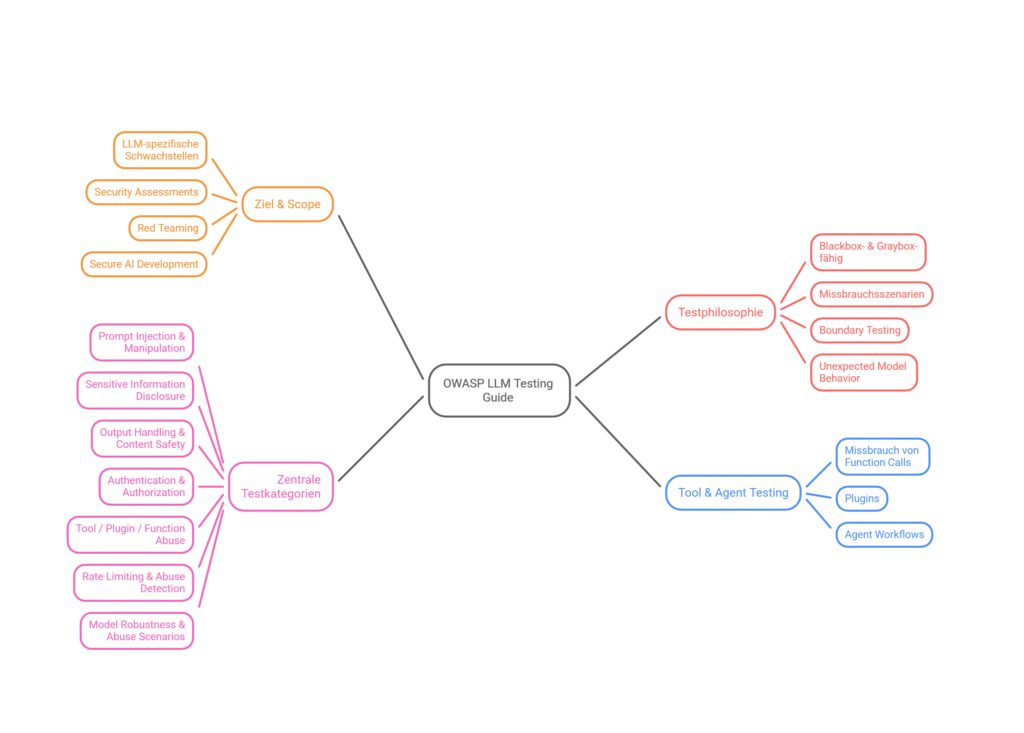
OWASP Top 10 for LLM Applications
The 10 most critical security risks for large language models — the foundation of our testing methodology.
Prompt Injection
Malicious instructions in inputs that manipulate LLM behavior.
Sensitive Information Disclosure
Confidential data exposed through outputs or configurations.
Supply Chain
Compromised third-party models, datasets, or libraries.
Data & Model Poisoning
Manipulation of training or fine-tuning data for backdoors.
Improper Output Handling
LLM outputs forwarded to downstream systems without validation.
Excessive Agency
Too much autonomy for LLM agents — unintended actions.
System Prompt Leakage
System prompts are disclosed or inferred.
Vector & Embedding Weakness
Attacks on RAG pipelines and embedding databases.
Misinformation
False or misleading information that appears credible.
Unbounded Consumption
Excessive resource consumption through uncontrolled inference requests.
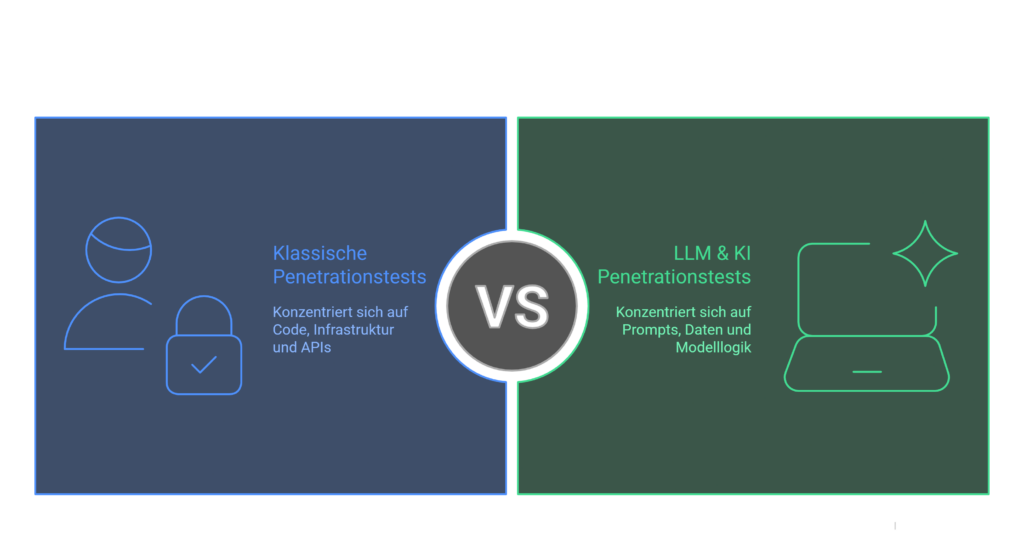
Vergleich von Web- und KI-Anwendungssicherheit
Applikationssicherheit bleibt das Fundament für NIS2 und AI Act — LLMs erweitern die Angriffsfläche um Prompts, Kontextdaten und agentische Workflows.
- Injection, Broken Access Control, XSS, SSRF auf HTTP/API-Ebene
- Stateful Sessions, serverseitige Validierung, bekannte OWASP-Web-Top-10-Muster
- Fokus: Requests, Responses, serverseitige Logik
- Prompt Injection, kontextbasierte Manipulation, Jailbreaks
- RAG/Embeddings, Tool-Calling, Multi-Agent-Ketten, Datenexfiltration
- Fokus: Kontextfenster, Policies, agentische Entscheidungen
OWASP ASVS 5.0 bündelt ~350 Security Requirements für Anwendungen. OWASP ASVS 5.0 — vollständige Seite →
Produktionsnahes KI-Security-Testing
KI-Pentesting mit technischer Tiefe — strukturiert, reproduzierbar und auditfähig für reale Produktionsumgebungen.
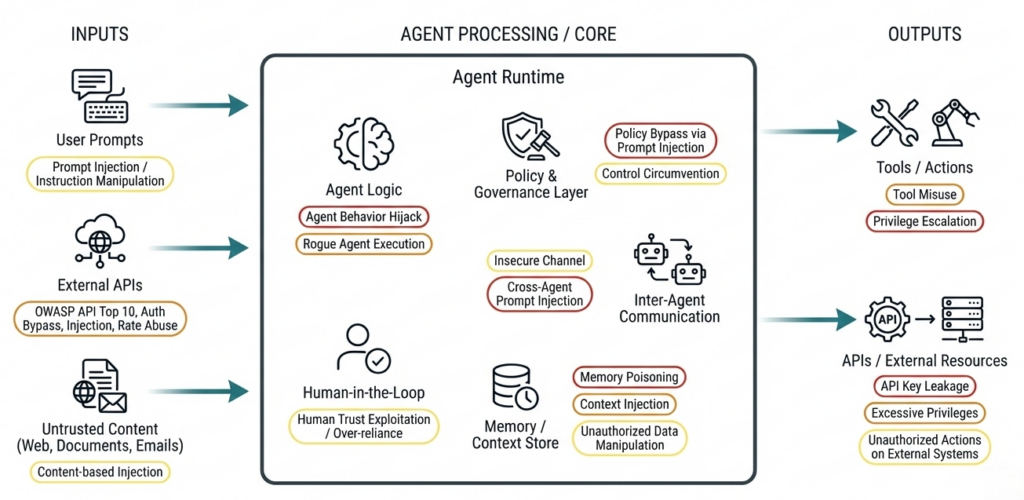
Agentic AI: more autonomy = more attack surface
Autonomous agents execute tools and retain context — risks that classical security tests often miss. Reference: OWASP Top 10 for Agentic Applications (2026).
Reale Angriffe auf Agentic AI Systems
- Tool misuse, goal hijacking & memory leaks
- Insecure tool selection & context chaining
- Identity abuse (human ↔ agent)
- Prompt injection in multi-agent workflows
- Model confusion & delegation risks
We systematically check: which actions agents are allowed to perform, how context flows between agents, tools and workflows, and how secure decisions, loops and tool executions are.
Security & technical risks
Hijacking, prompt injection, data exposure — an expanded attack surface.
Operational & control risks
Excessive trust without a human-in-the-loop can mean losing control.
Business & compliance
AI Act, GDPR — structured AI risk management.
Societal & ethical
Disinformation, deepfakes — secure-by-design and regular testing.
AI & LLM Security CTF
Typische Angriffspfade wie Prompt Injection, Tool- und Agent-Missbrauch sowie unsichere Ausgabe- und Datenverarbeitung — praktisch nachvollziehbar, realistisch und enterprise-tauglich.
Datenabfluss verhindern: Ihre KI-Nutzung sicher im Griff
KI schafft Effizienz, erhöht aber das Risiko unkontrollierten Datenabflusses — von HR und Finance bis zu IP.
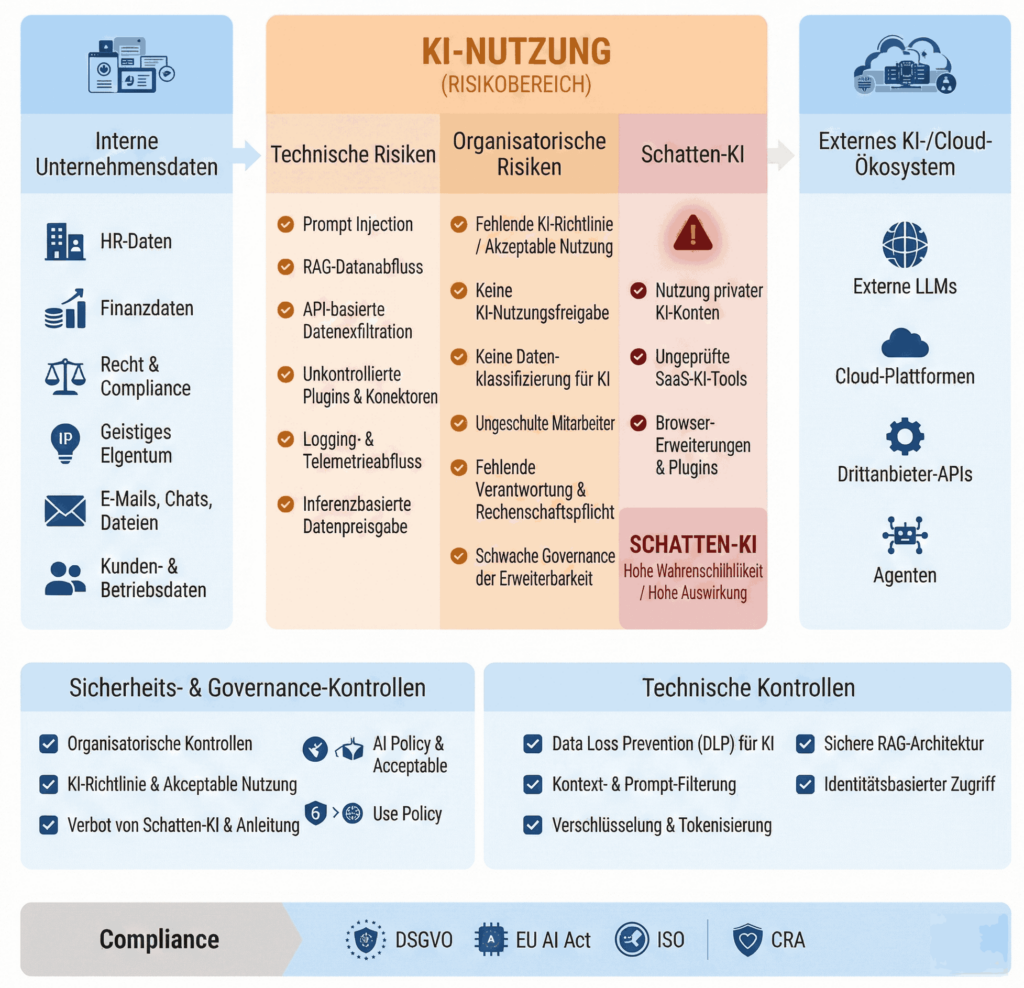
Erhebung
Welche Daten landen freiwillig oder unbewusst im Kontext?
Verarbeitung
Wo werden Inhalte gespiegelt, gecacht oder weitergeleitet?
Exfiltration
Können Prompts oder Antworten sensible Felder rekonstruieren?
Kontrolle
DLP, Labels, Policy-Engines, Logging — messbar validieren.
Microsoft Copilot Risiken
Unterschiedliche Copilot-Varianten — unterschiedliche Datenflüsse und Kontrollbedarfe.
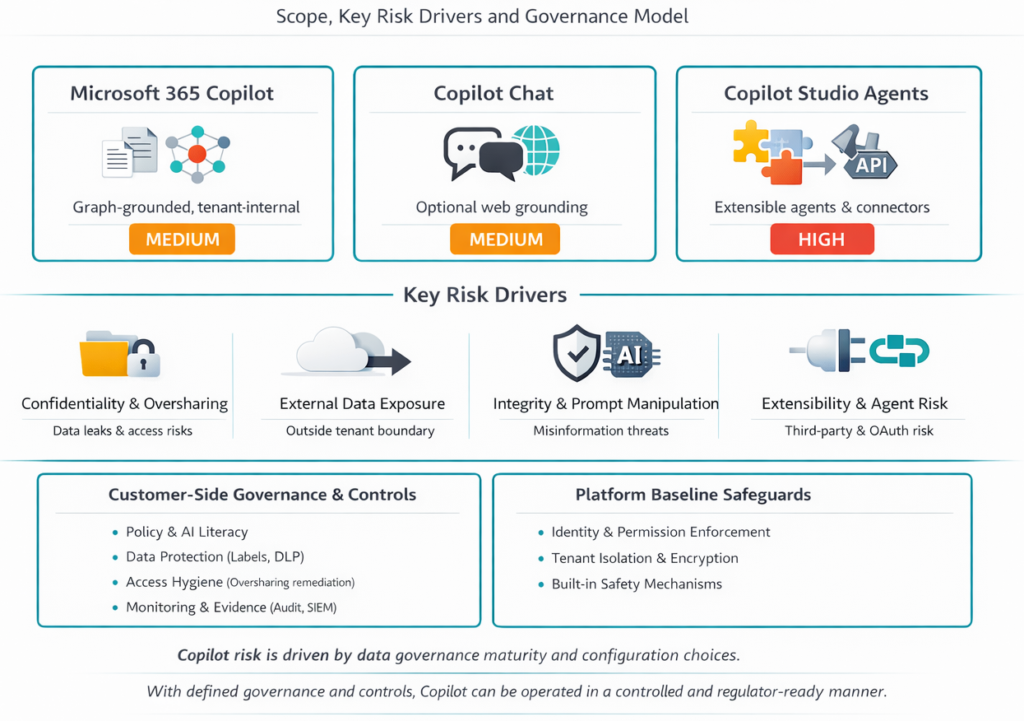
Microsoft 365 Copilot
Mittleres Risiko — Datenlecks, Zugriffskontrollen, Klassifizierung, Monitoring.
Copilot Chat
Erhöhtes Risiko durch Web-Integration: Datenabfluss, Prompt-Manipulation.
Copilot Studio Agents
Hohes Risiko — autonome Agents, OAuth, Drittanbieter ohne Risikomanagement.
Was Sie erhalten
Risk-Prioritized Findings
Real attack paths with clear prioritization by business impact and risk.
Reproducible Test Cases
Traceable, technically reproducible test cases and proof-of-concepts.
Concrete Mitigations
Clear security controls and remediation measures for engineering & governance.
Executive-Ready Reporting
Management-level executive summary for audits, compliance, and decision-makers.
Agentic AI Security Testing
We simulate targeted exploitation scenarios against agentic AI architectures: tool misuse, goal hijacking, memory leaks, prompt injection in multi-agent workflows, and identity abuse.
Compliance & Regulatory
AI risks are not a future question – they arise during operations. Our tests create robust evidence for EU AI Act, NIS2, DORA, GDPR, ISO 27001 & ISO 42001.
Was wir testen
What Does an AI & LLM Pentest Do?
Model Discovery & Recon
Analysis of all AI endpoints, APIs, and context data to make the entire attack surface visible.
Prompt Injection & Jailbreak
Targeted simulation of inputs that can induce models to perform unauthorized actions.
Agentic AI Attacks
Tests against autonomous agents, workflow control, and context chaining.
Data & API Risks
Detection of data leaks, unsecured APIs, and sensitive context exposures.
From Framework to Implementation
First understand, then test, then govern, then protect permanently. Assess → Test → Govern → Protect.
OWASP AIVSS — Bewertung agentischer KI
CVSS allein reicht nicht — AIVSS kombiniert CVSS v4.0 mit AARS (Agentic Risk Score). Qualitative Entscheidungen: Defer, Scheduled, Out-of-Cycle, Immediate.
GenAI Red Teaming
Discover
Oberflächen, Modelle, Tools, Datenquellen kartieren.
Attack
Szenarien aus OWASP LLM/Agentic, custom Abuse Cases.
Measure
AIVSS, Repro-Schritte, Severity-Workshop.
From secure AI systems to audit-ready compliance
Classical web vulnerabilities meet AI-specific risks: prompt injection, data and model poisoning, insecure tool and RAG paths. Our pentests and OWASP-aligned reviews deliver reproducible evidence — matching what regulators and auditors expect under "robustness", "cybersecurity" and risk management.
Obligations that demand technical depth
For high-risk AI systems, documented risk analyses and effective technical measures are mandatory. Pentest findings substantiate Art. 15 (cybersecurity, robustness) and strengthen risk management under Art. 9. Transparency and data obligations (Art. 10, 13) can be backed up with clear evidence on data flows, logging and the model supply chain.
- Art. 9 — risk management system: continuous, documented, tied to the risk class
- Art. 10 — data & governance: quality, bias monitoring, representative training and operating data
- Art. 15 — accuracy, robustness, cybersecurity: targeted attack simulations and hard PoCs
Critical services & stricter evidence requirements
AI components in critical and essential sectors are subject to stricter security and evidence requirements. Regular security assessments, vulnerability handling and robust risk artefacts are part of the expected baseline.
- Regular security assessments of the AI infrastructure
- Demonstrable risk artefacts for regulatory conversations
- Integration into NIS2 incident-response processes
AI Management System (AIMS)
The AI management system requires operational security and continuous evaluation. Technical tests (pentest, red team, targeted LLM/agent scenarios) deliver measurable inputs for control, improvement and certification discussions.
- Measurable inputs for the AIMS control system
- Combinable with ISO 27001 for shared evidence
- Foundation for certification discussions and audits
Financial sector — treat AI like productive IT
The ICT attack surface grows with every chat interface, copilot and autonomous workflow. DORA requires systematic testing of digital resilience; from the regulator's perspective, the same standards apply to AI-supported systems as to classical IT.
- ICT risk management incl. AI supply chains and outsourcing
- Demonstrable test and review cycles, not just point measures
- Documentable findings for internal audit and regulatory conversations



Häufig gestellte Fragen
Protect Your AI Systems Now
Contact us for a customized LLM Security Assessment – practical, audit-ready, and tailored to your requirements.
Erstberatung buchen